| Active with remarks |
|---|
| This application needs additional settings. Please follow the documentation below to create your own connectionUnique, active service acces point to a network. There are different types of connections (API key, Oauth…). More. |
With the Google Cloud Speech modulesThe module is an application or tool within the Boost.space system. The entire system is built on this concept of modularity. (module - Contacts) More in Boost.spaceCentralization and synchronization platform, where you can organize and manage your data. More IntegratorPart of the Boost.space system, where you can create your connections and automate your processes. More, you can retrieve the statusCreate statuses for each module separately to create an ideal environment for efficient and consistent work. More of asynchronous speech recognition, and start asynchronous and synchronous speech recognitions.
Prerequisites:
-
A Google Cloud Platform account
-
Google Cloud Credentials (OAuth Client ID and Client Secret)
To get started with Google Cloud Platform, create an account at Google Cloud Speech-to-text.
![[Note]](https://docs.boost.space/wp-content/themes/bsdocs/docs-parser/HTML/css/image/note.png) |
Note |
|---|---|
|
Boost.space Integrator‘s use and transfer of information received from Google APIs to any other app will adhere to Google API Services User Data Policy. |
To connect Google Cloud Speech to Boost.space Integrator:
-
Log in to your Make account, add a Google Cloud Speech moduleThe module is an application or tool within the Boost.space system. The entire system is built on this concept of modularity. (module - Contacts) More to your scenarioA specific connection between applications in which data can be transferred. Two types of scenarios: active/inactive. More, and click Create a connection.
-
Optional: In the Connection name field, enter a name for the connection.
-
In the Client ID and Client Secret fields, enter the client credentials of your custom appCreate your own custom apps to be used in the integrator engine and share them with users in your organization..
-
Click the Sign in with Google button and select your Google account.
-
Review the access information and click Allow.
You have successfully established the connection. You can now edit your scenario and add more Google Cloud Speech modules. If your connection needs reauthorization at any point, follow the connection renewal steps here.
To obtain the client credentials, you must have access to Google Cloud Console and be able to create or edit the project.
-
Sign in to Google Cloud console using your Google credentials.
-
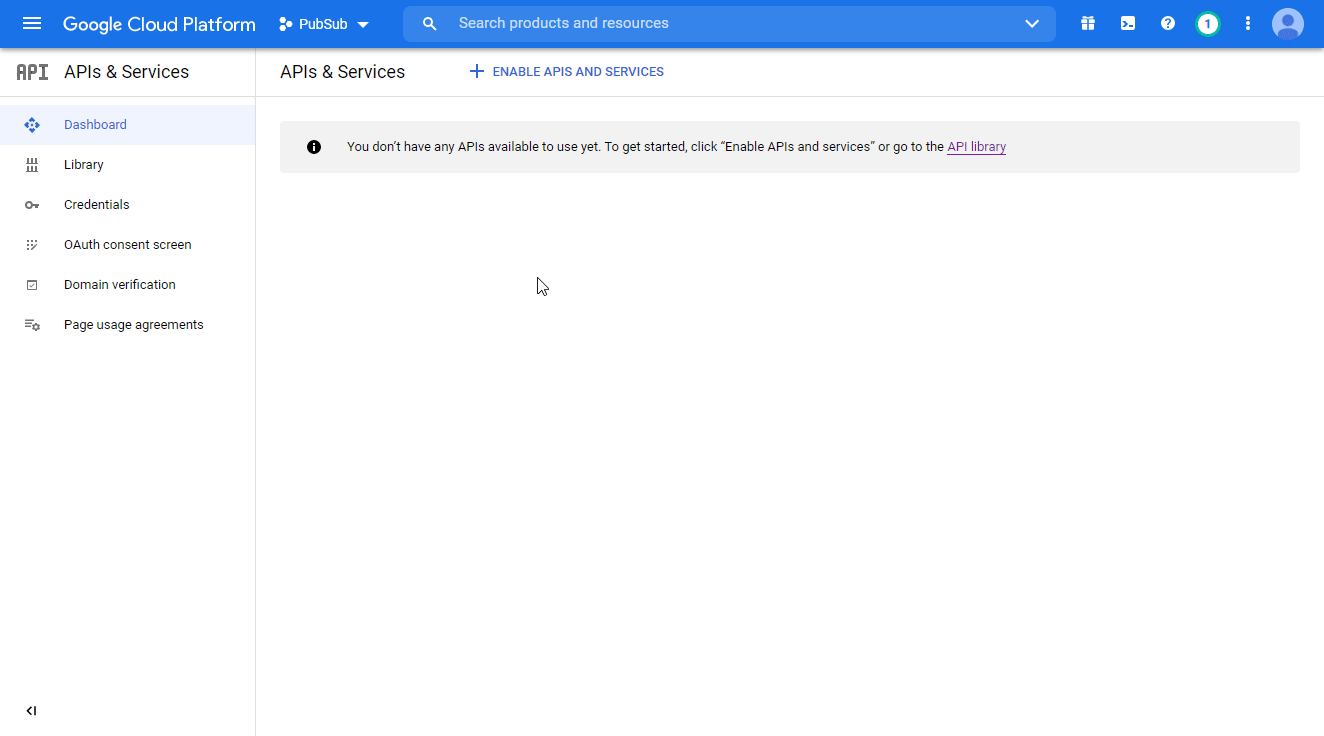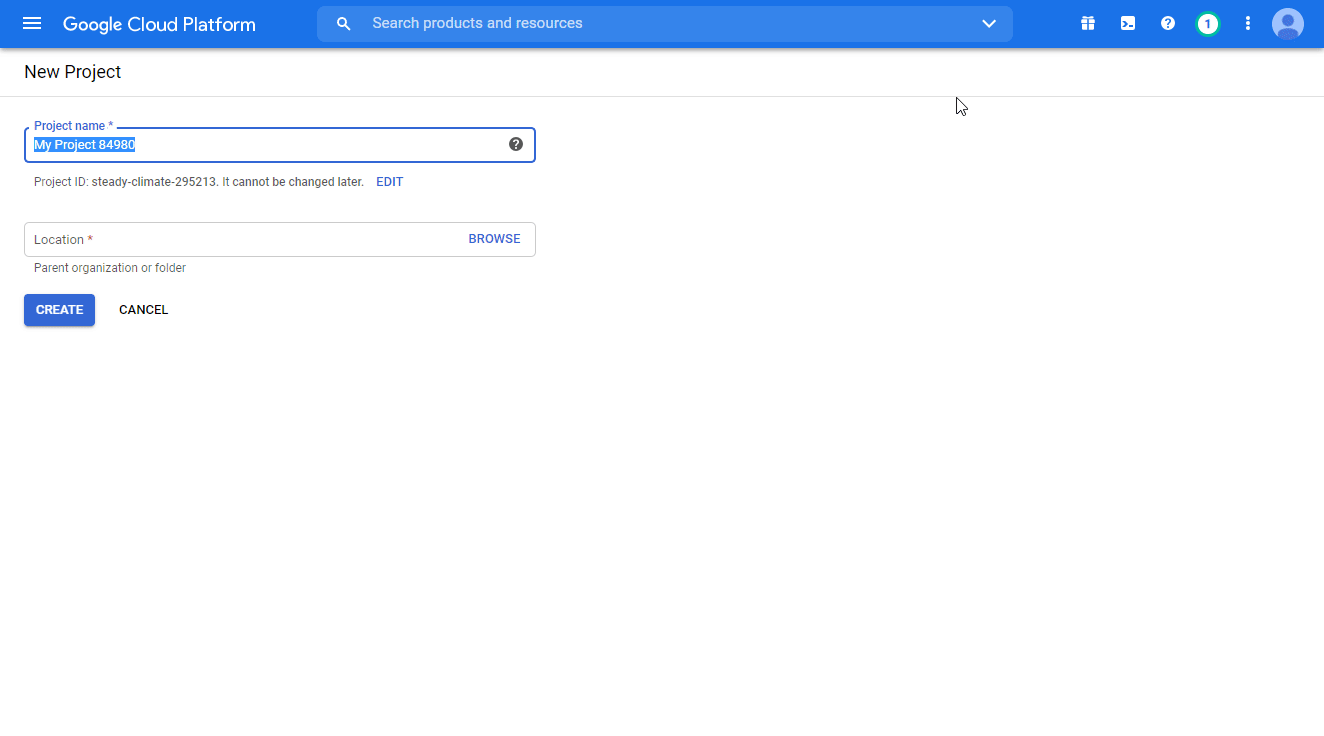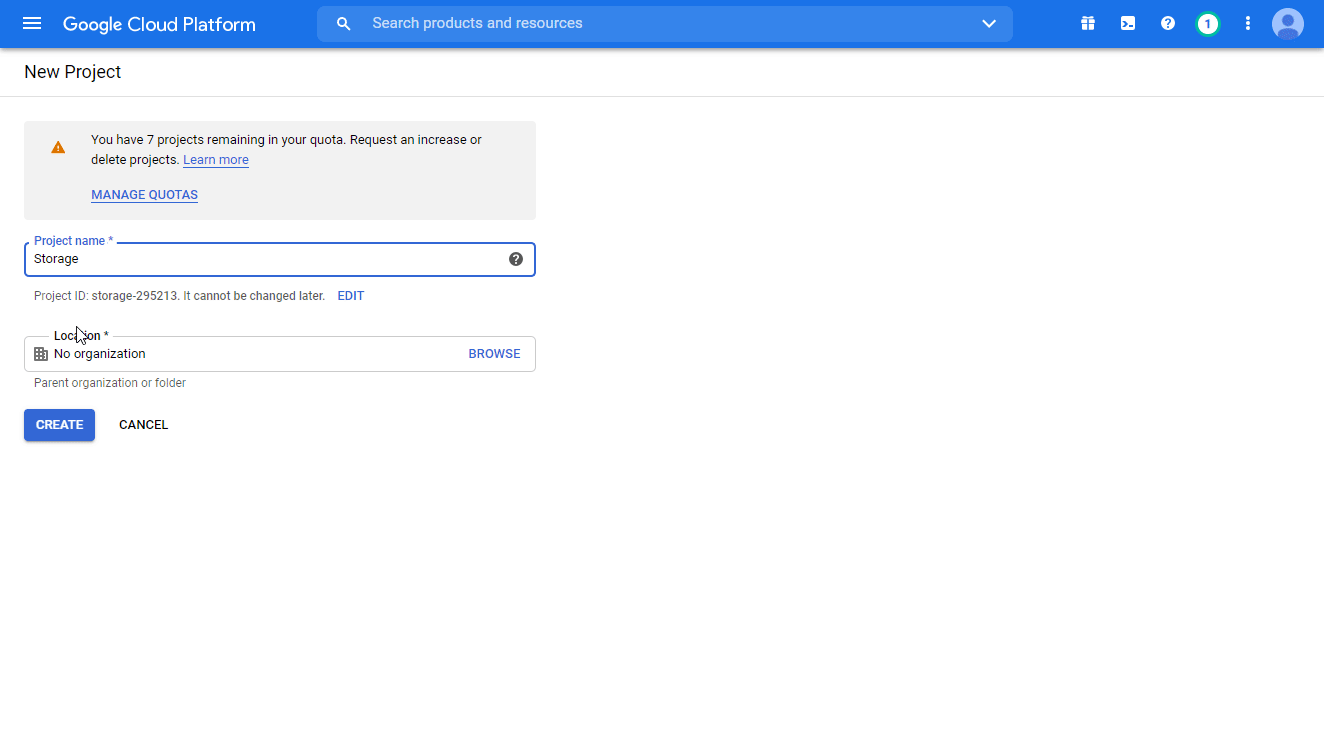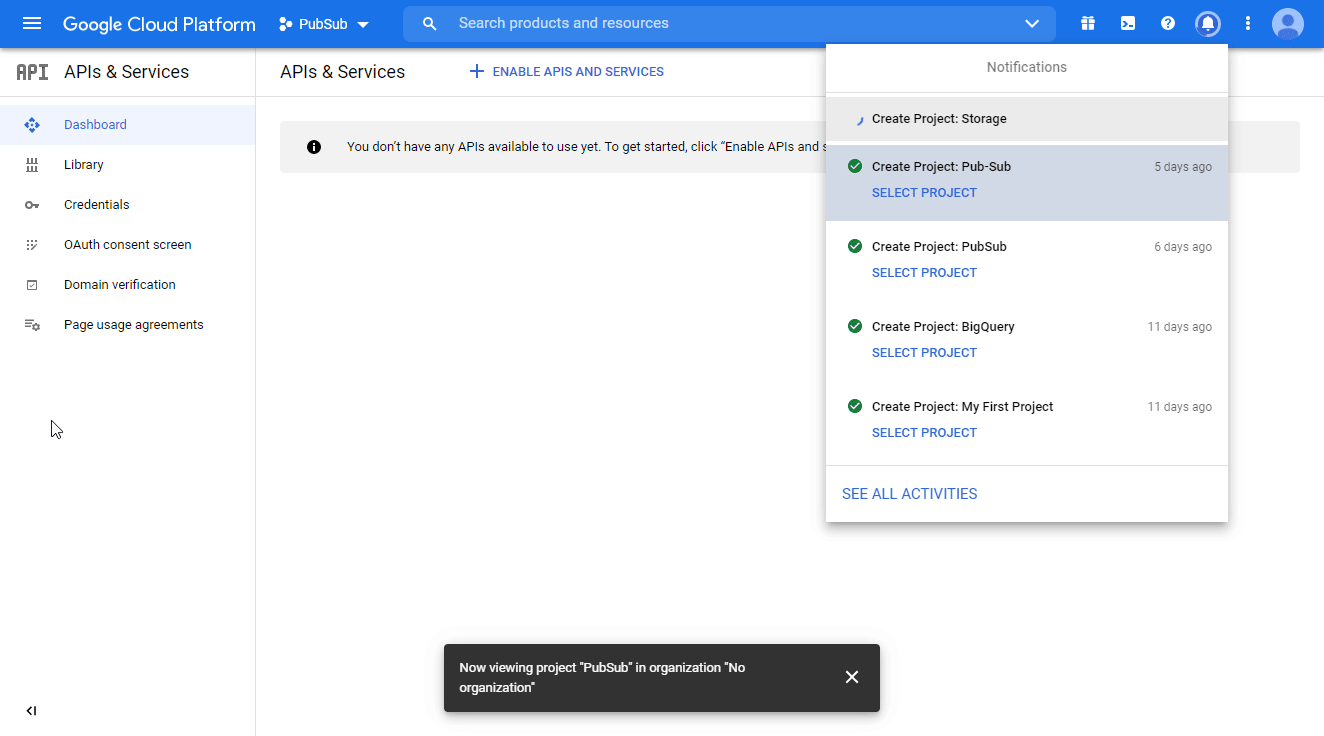
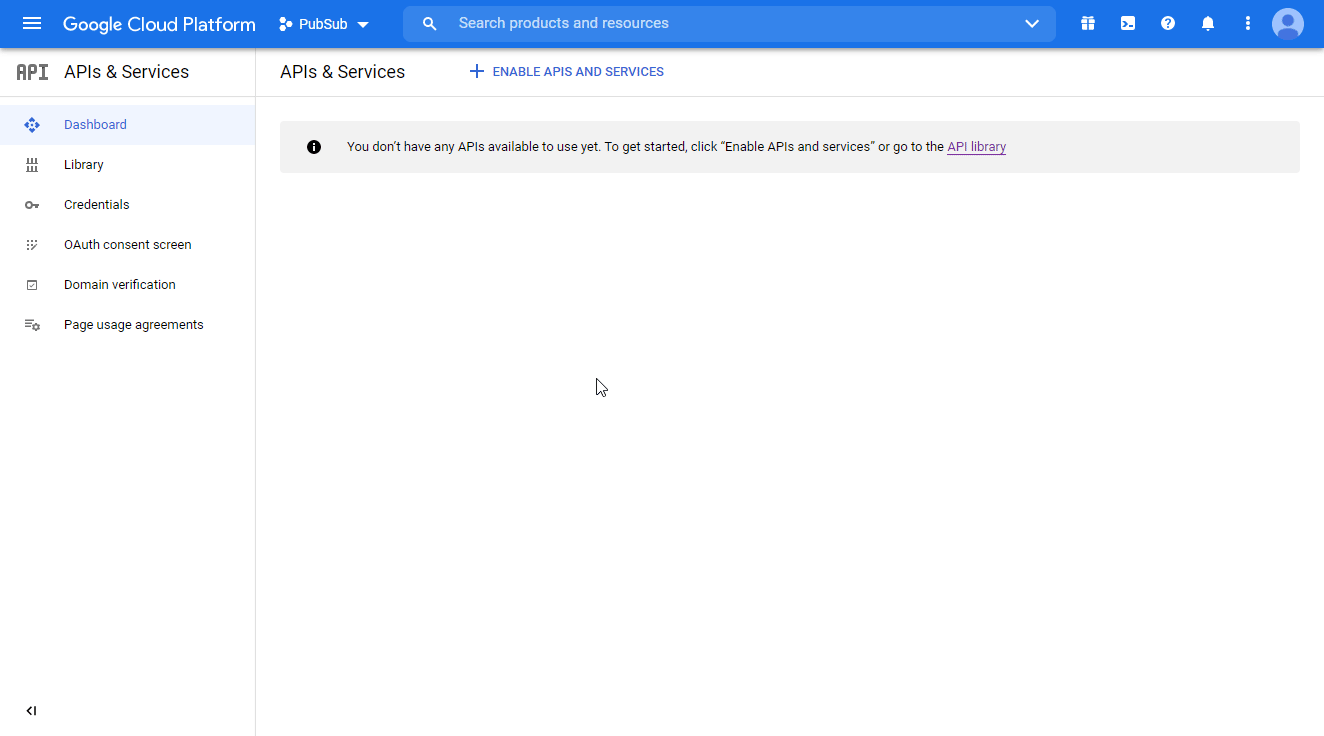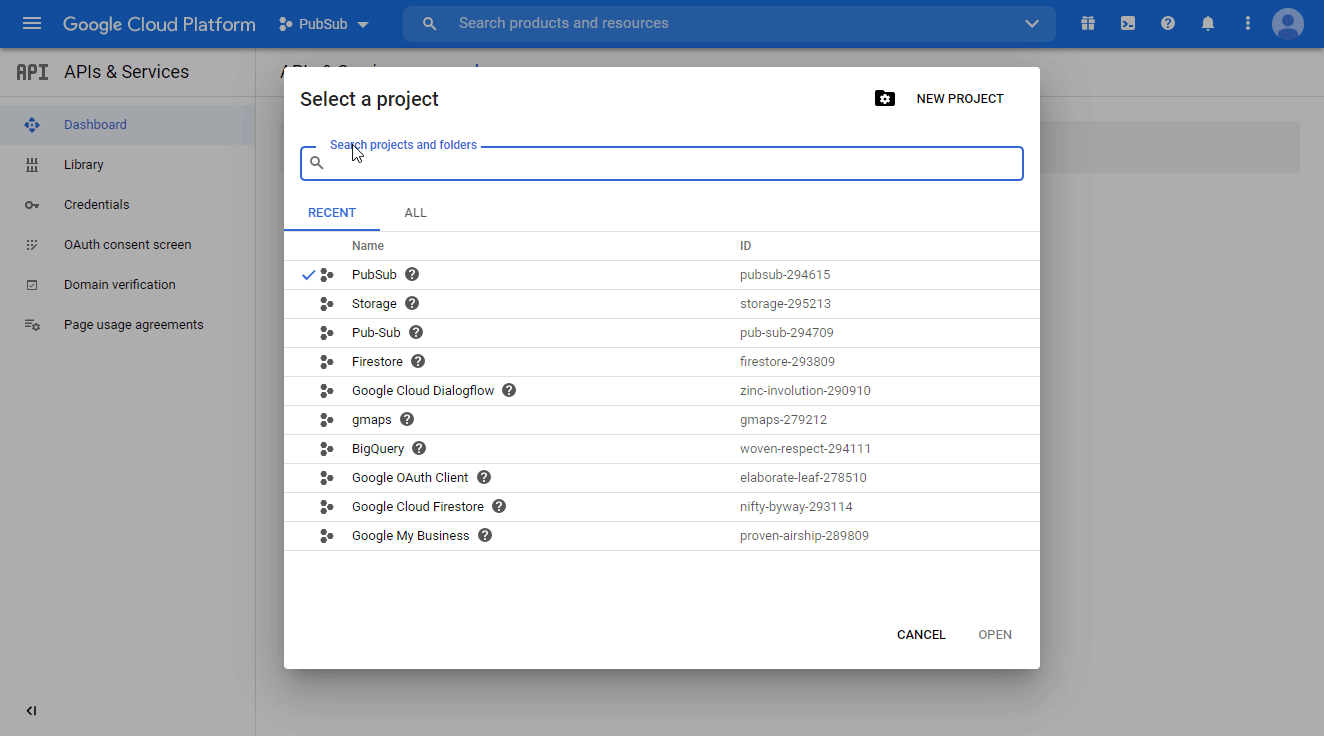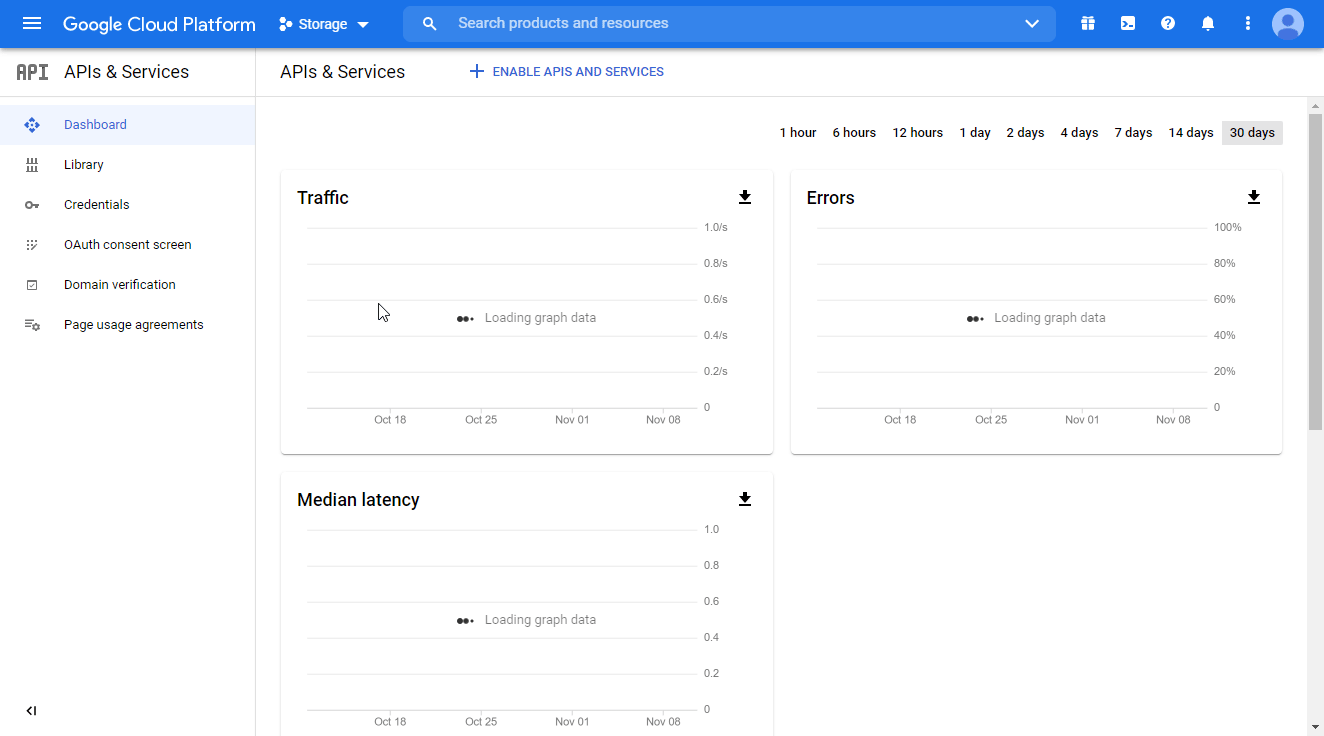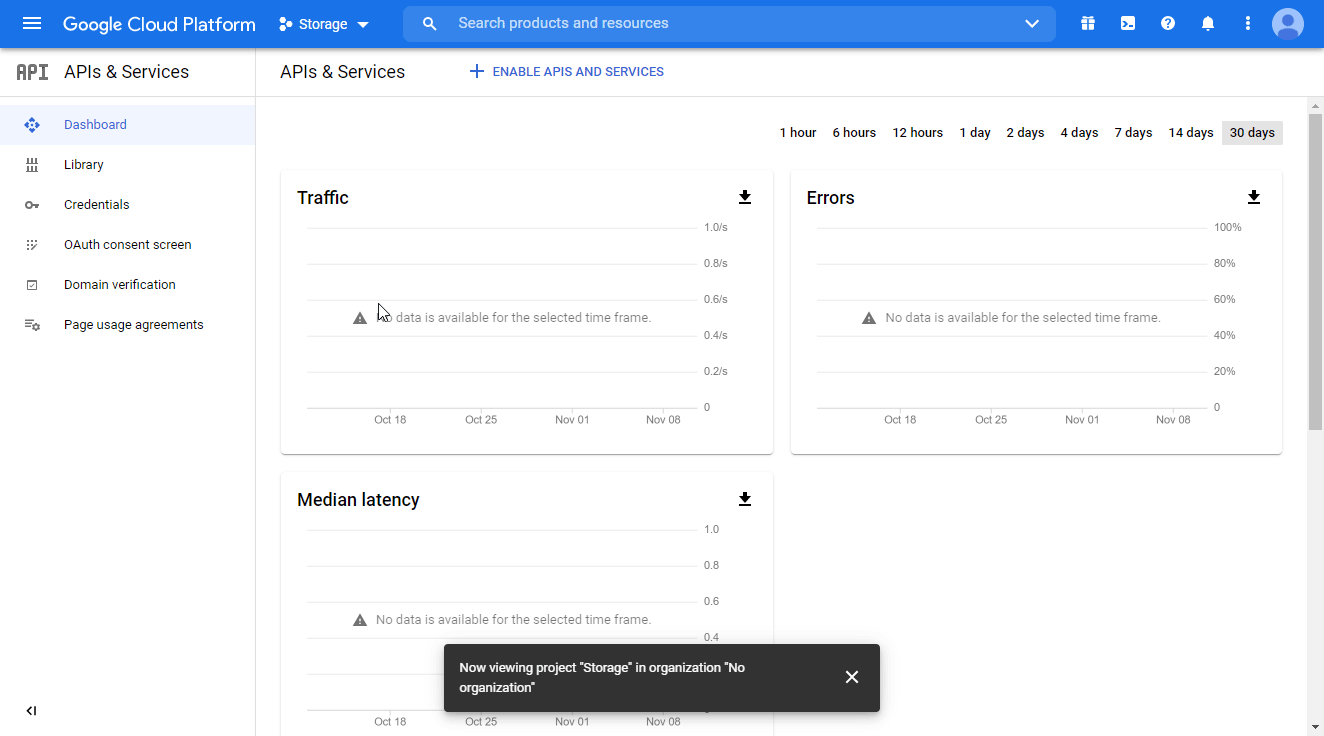
Click Select a project > NEW PROJECT. Enter the desired project name, and click the CREATE button.
-
Select the project you have created.
-
Go to APIs & Services > Library.
-
Search and enable the following required APIs:
The desired service option should display as you type. Select the API/service you want to connect to Boost.space Integrator.
-
Click the ENABLE button to enable the selected API.
-
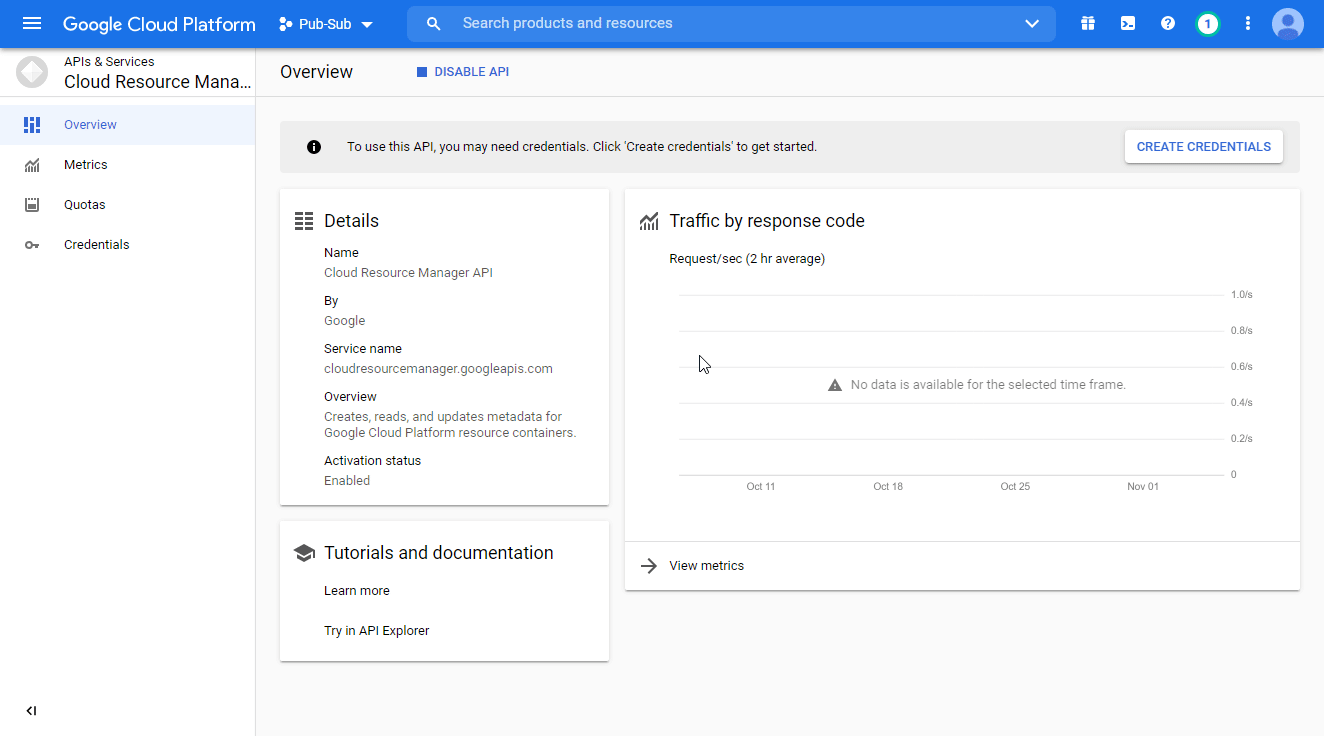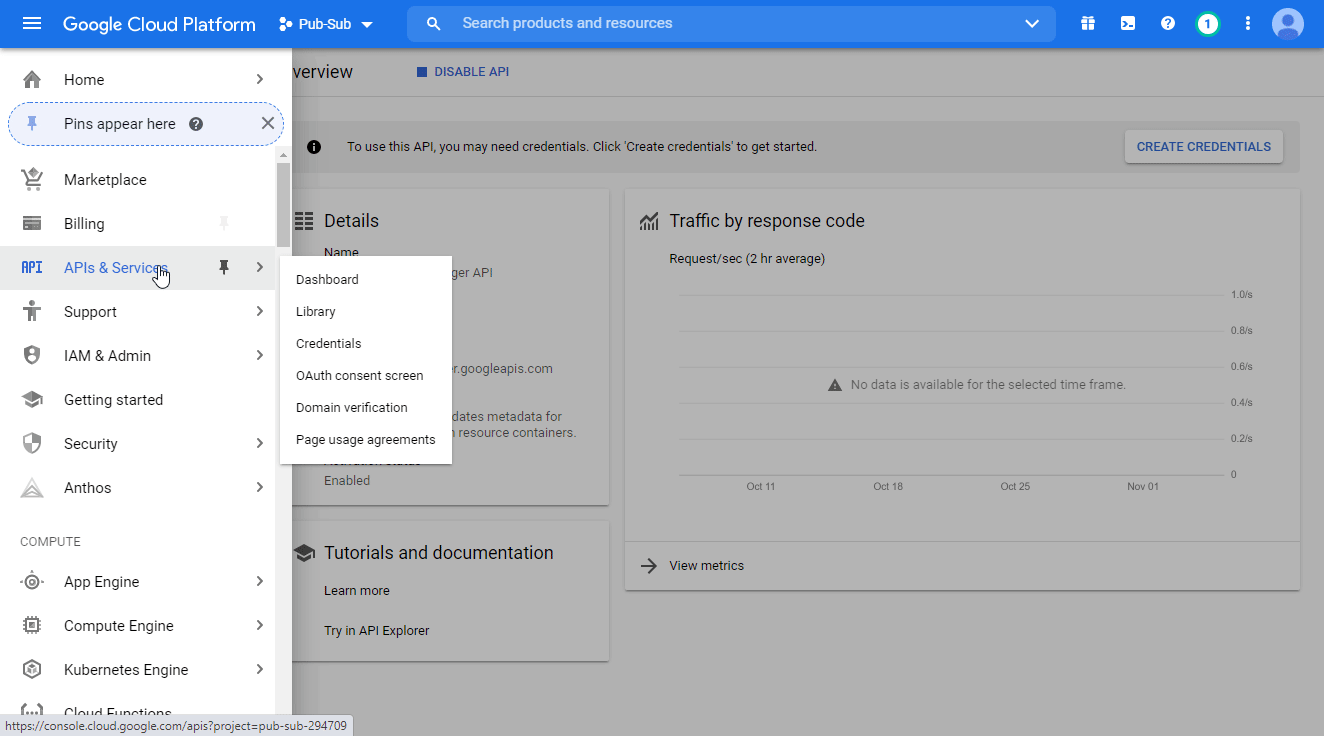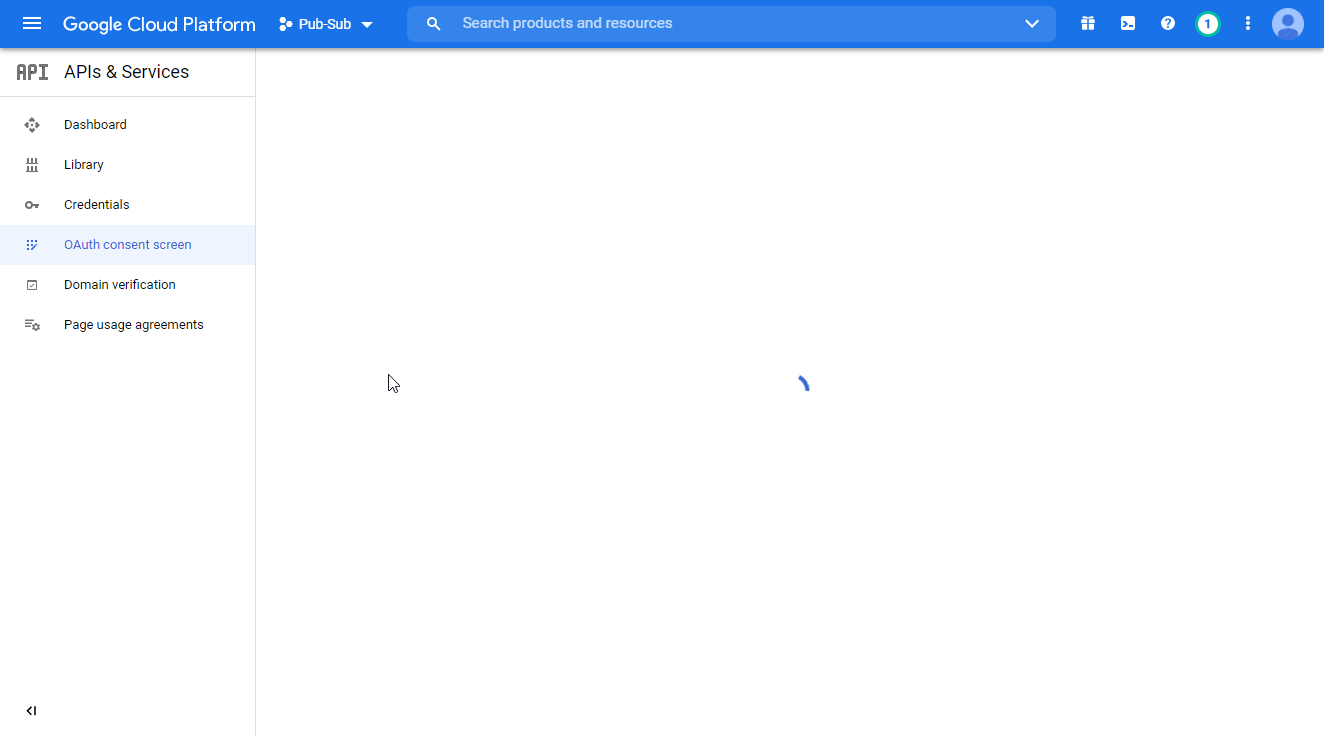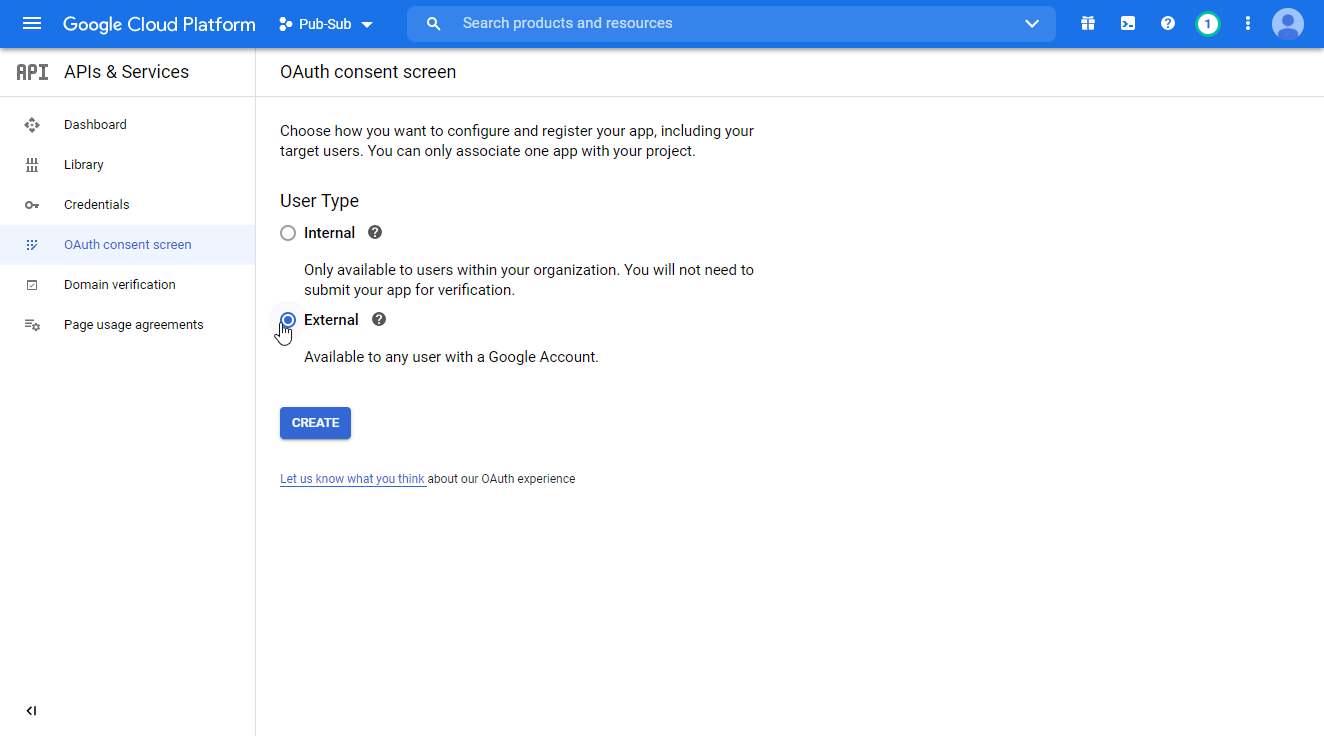
Navigate to APIs & Services > OAuth consent screen.
-
Choose the External option, and click the CREATE button.
Note You will not be charged when selecting this option! For more details, please refer to Google’s Exceptions to verification requirements.
-
Fill in the required fields as follows, and then click Save and Continue:
App name
Enter the name of the app asking for consent. For example,
Boost.space Integrator.Authorized domains
-
make.com -
integromat.com
-
-
You don’t have to set anything in the Scopes and Optional info sections. Click Save and Continue.
-
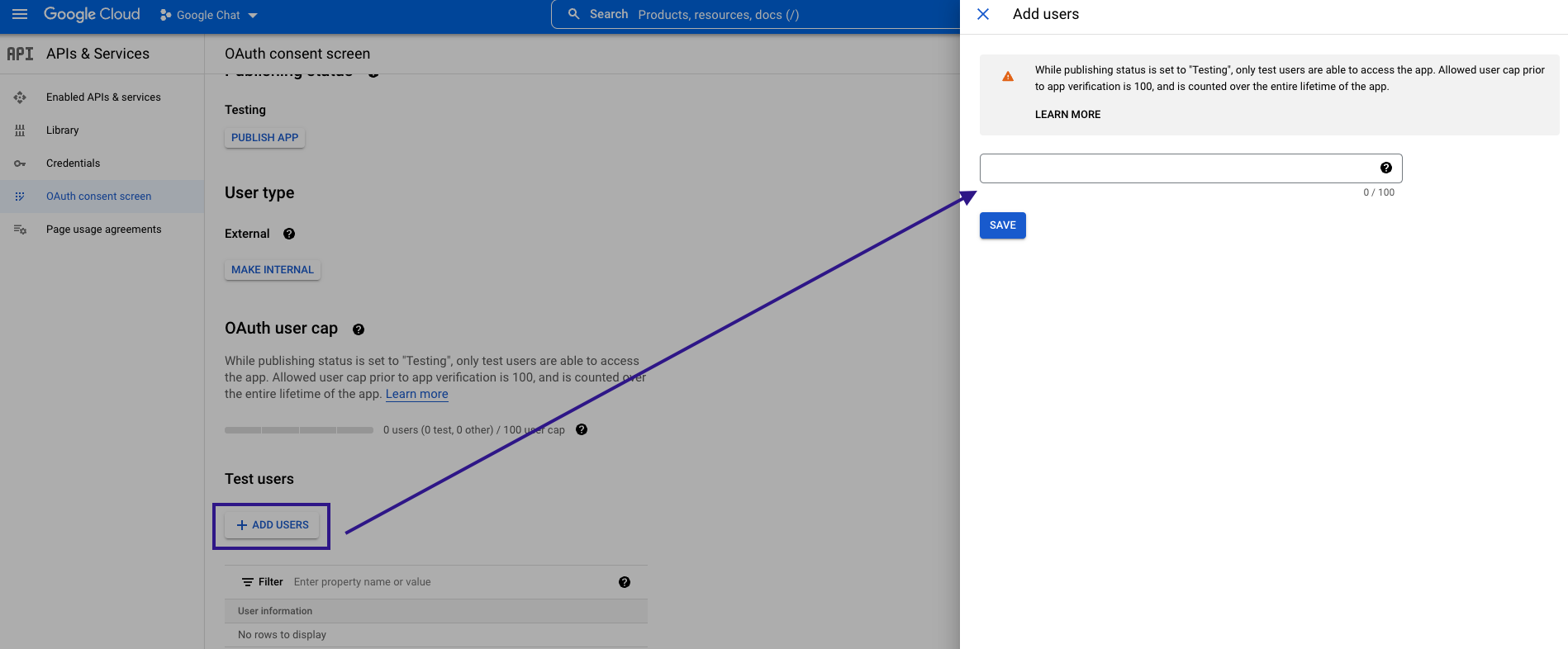
In the Test UsersCan use the system on a limited basis based on the rights assigned by the admin. More section, click ADD USERS and enter the testing userCan use the system on a limited basis based on the rights assigned by the admin. More email address to access the app.
-
Navigate to Credentials. Click the +CREATE CREDENTIALS and select the OAuth Client ID option.
-
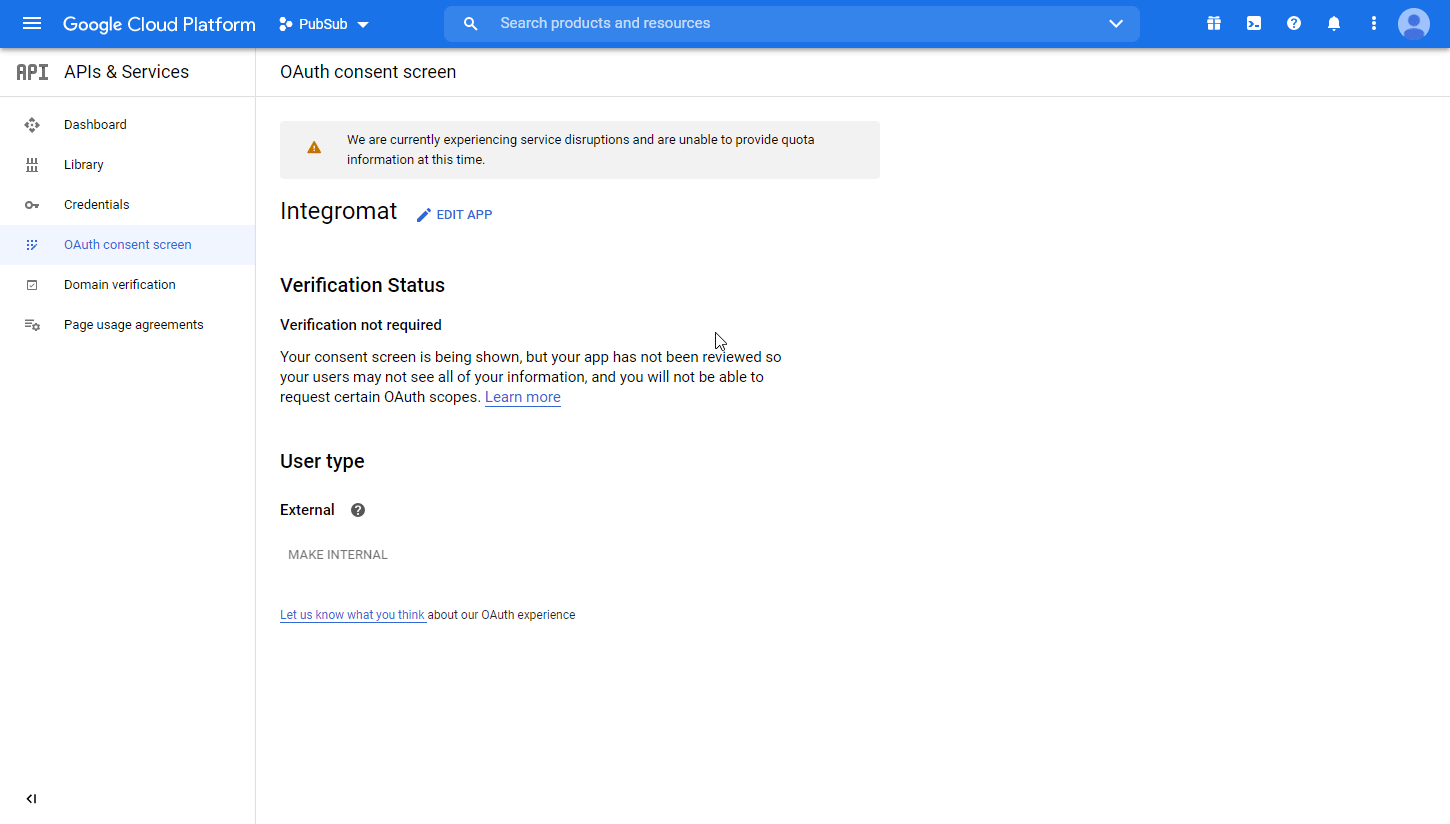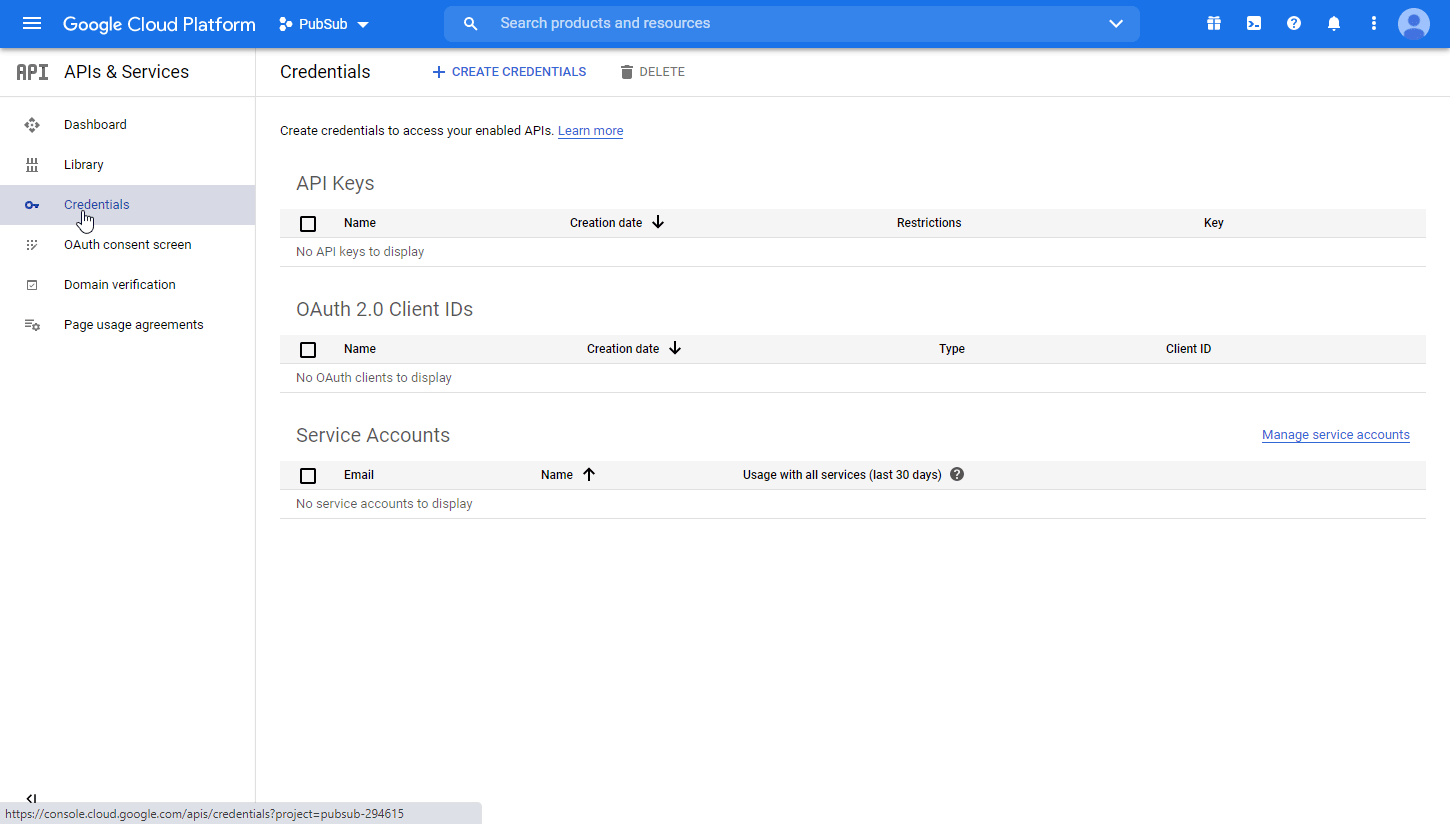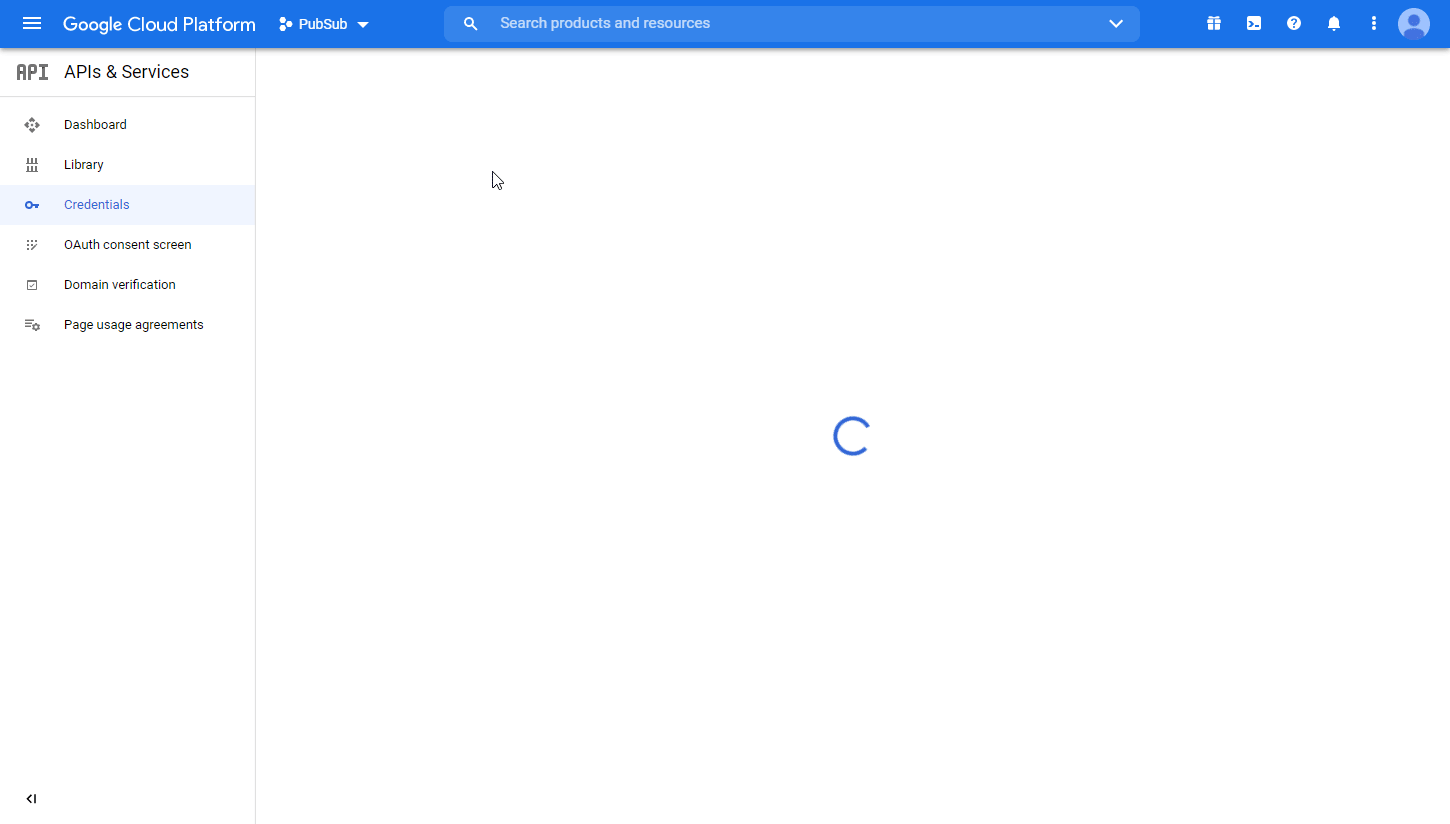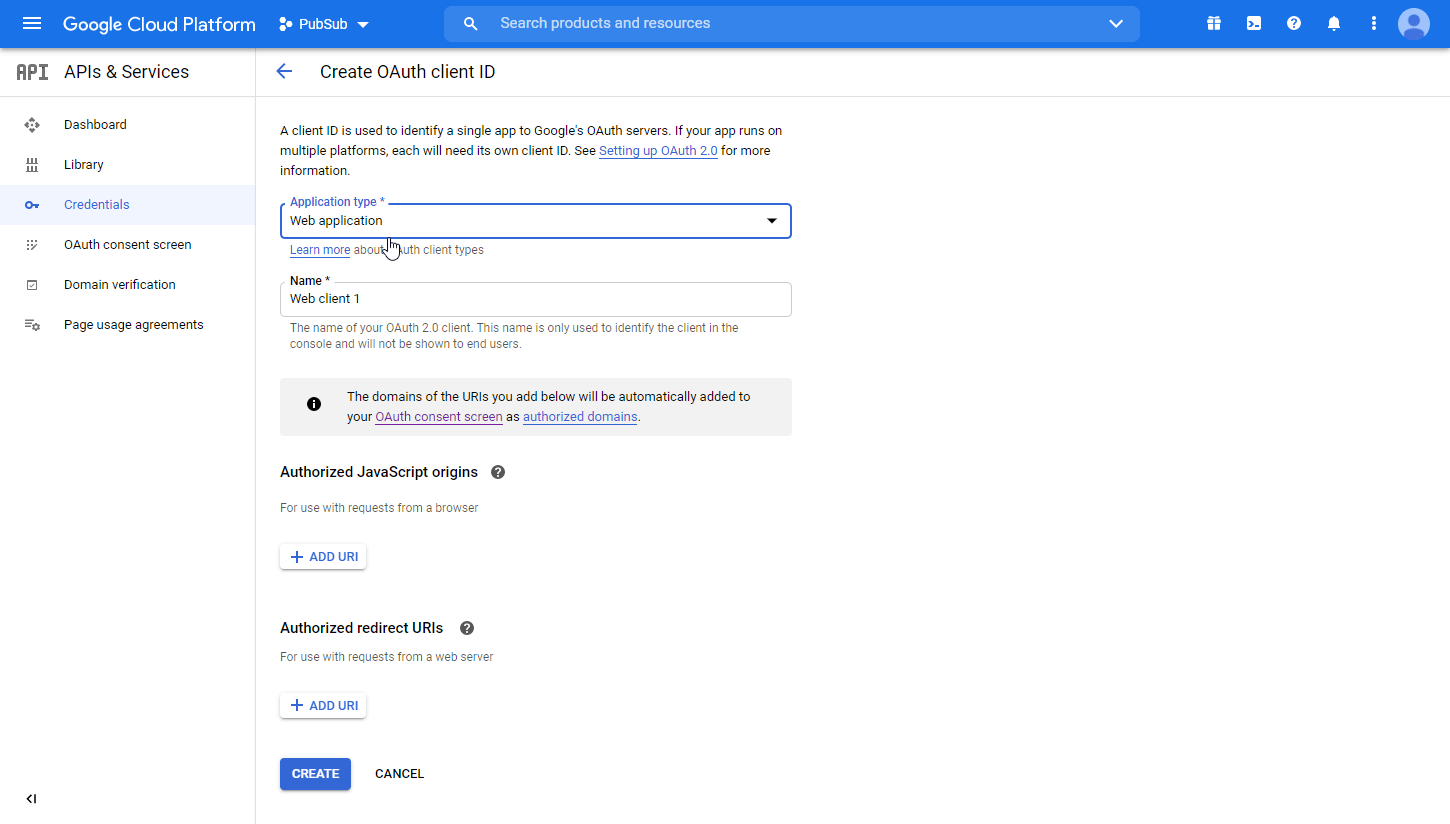
Fill in the required fields as follows, and then click the CREATE button to create the application:
Application type
web applicationName
Name of the application. For example,
Boost.space Integrator.Authorized redirect URIs
-
https://integrator.boost.space/oauth/cb/google-restricted -
For Google Cloud Speech, add
https://integrator.boost.space/oauth/cb/google-cloud-speech
-
-
A dialog containing the app’s Client ID and Client Secret is displayed. Save them in a safe place for later use.
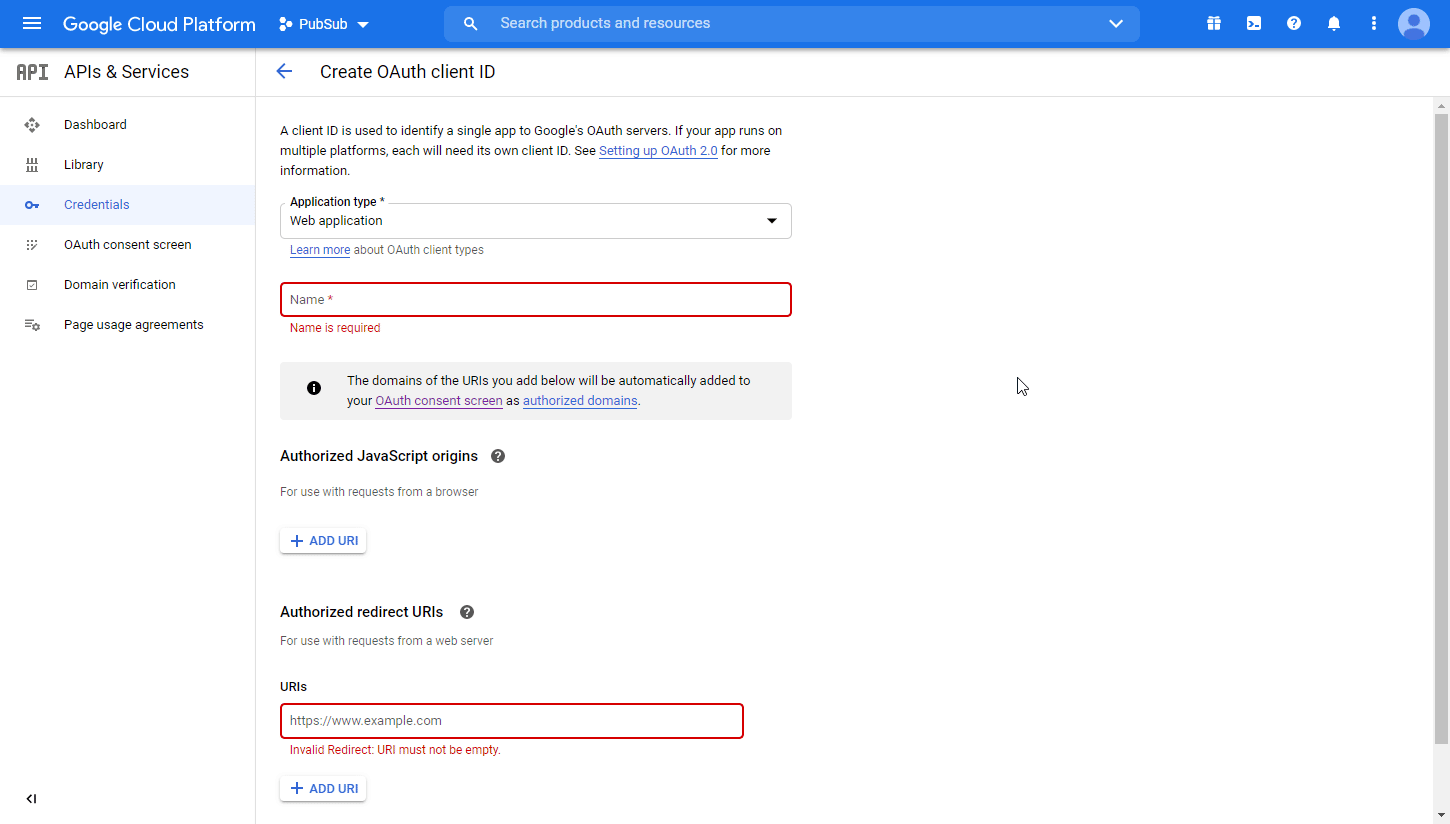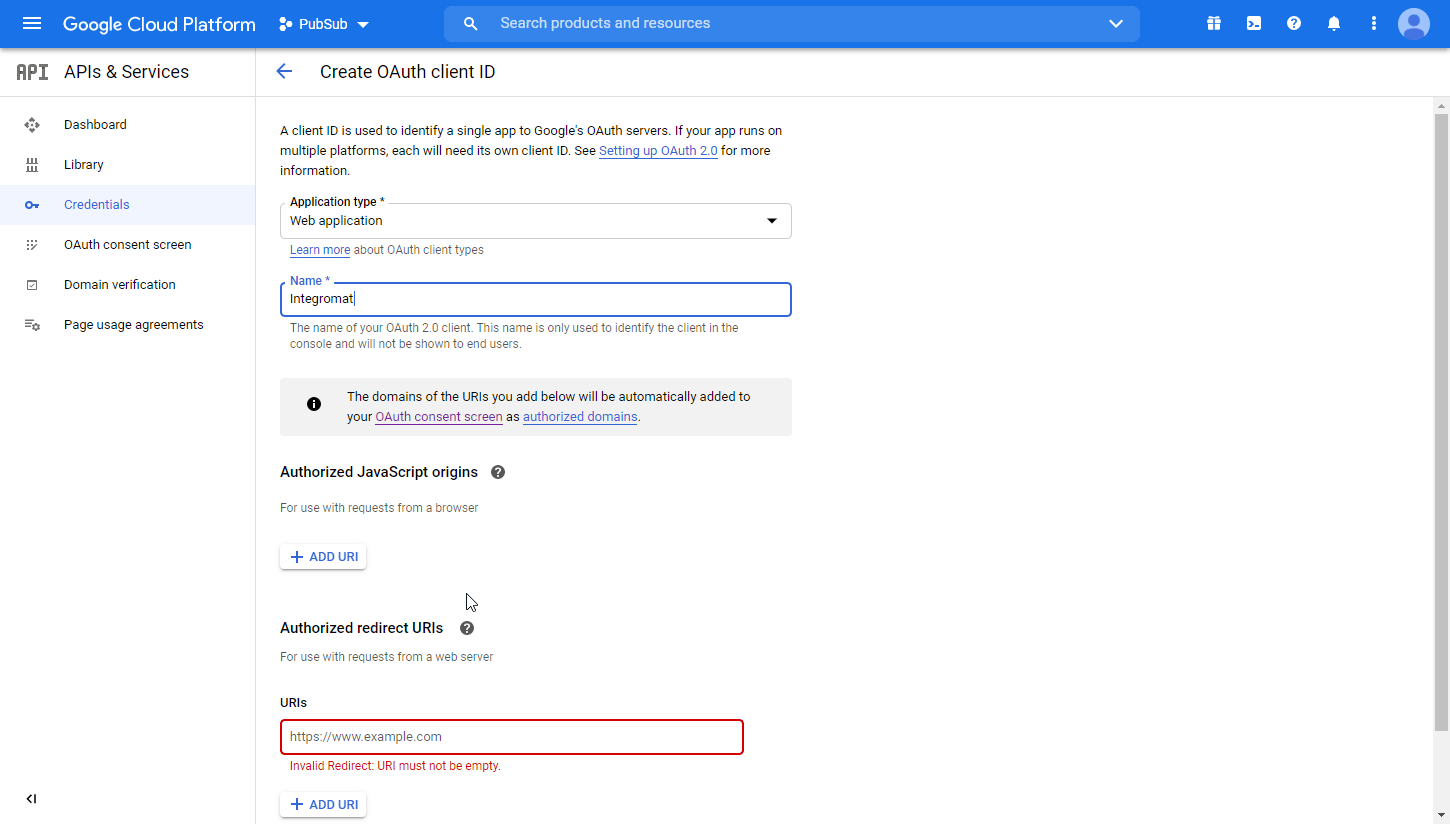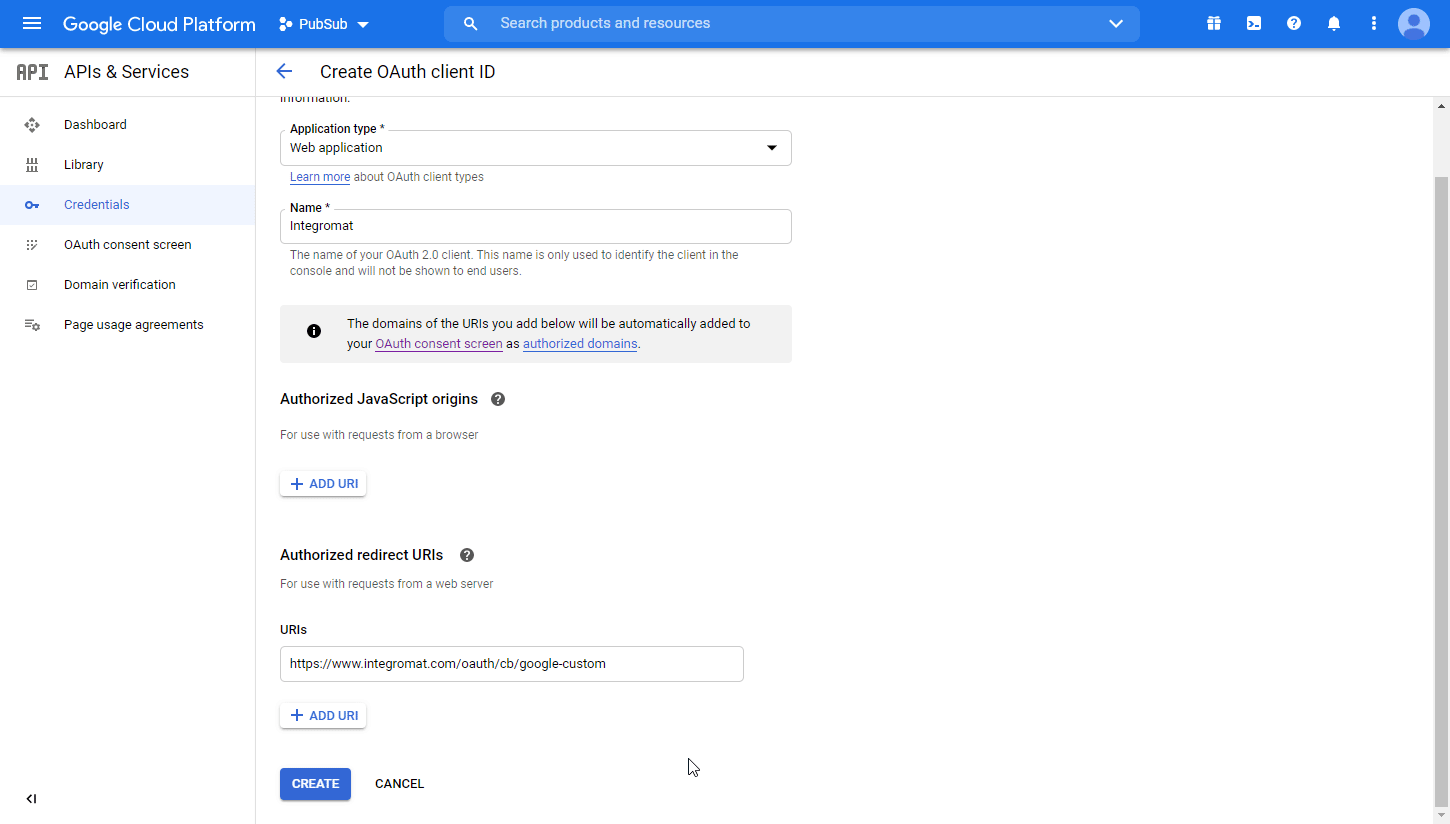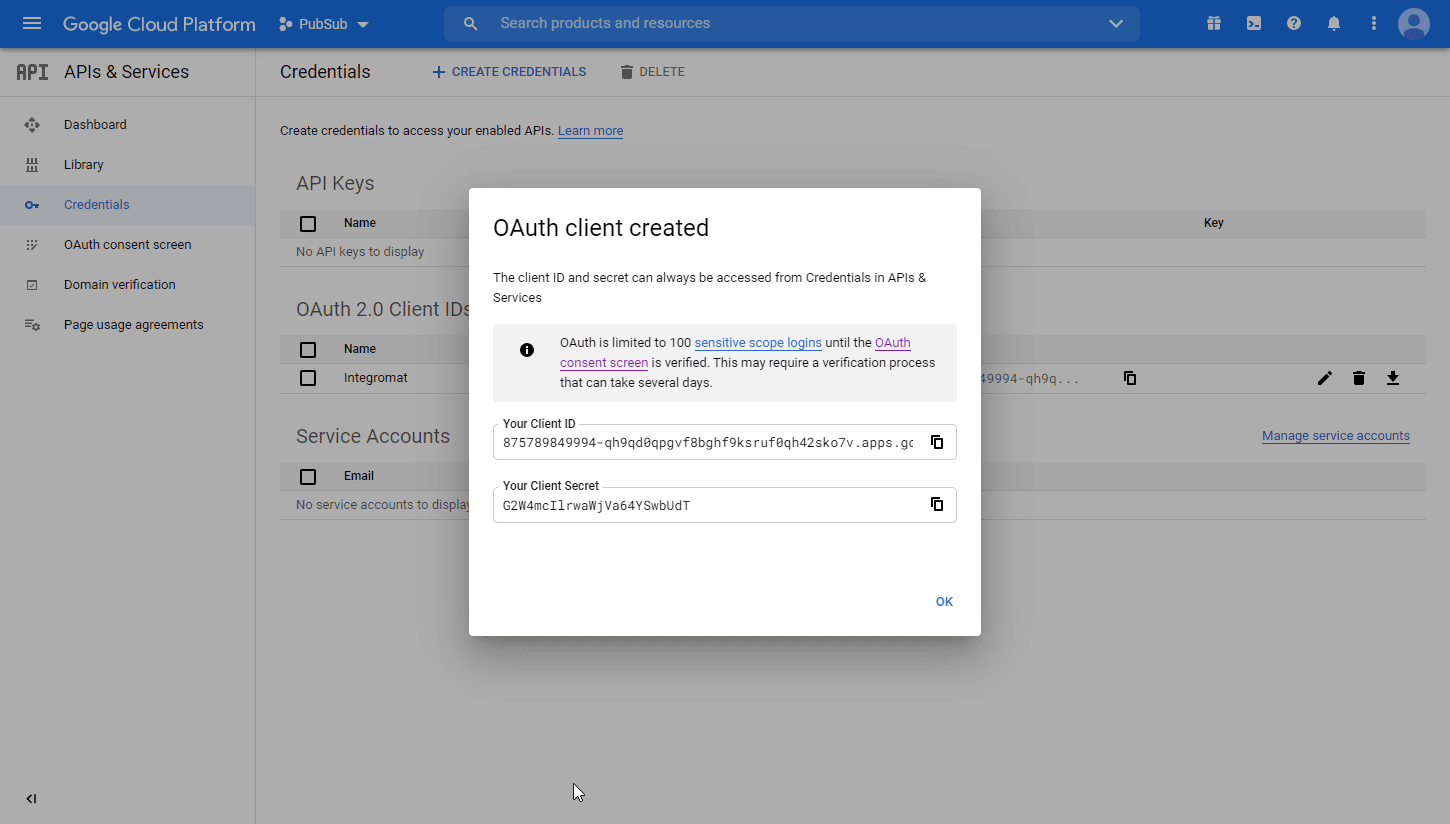
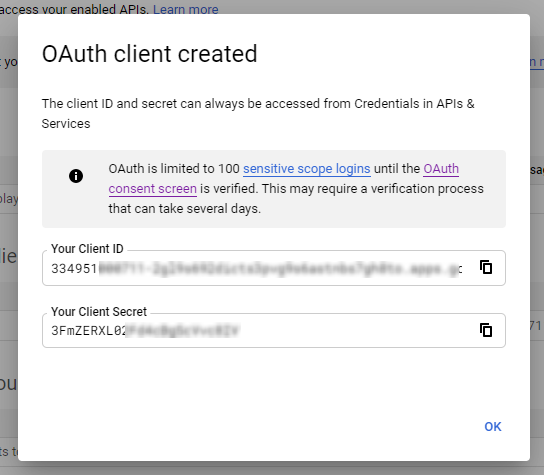
You have successfully created the client credentials.
|
Note |
|---|---|
|
If you are using custom appsCreate your own custom apps to be used in the integrator engine and share them with users in your organization. with publishing state, Testing, then you must set up the access tokenThe API token is a multi-digit code that allows a user to authenticate with cloud applications. More NOT TO be forced to re-authenticate every week after expiration. For more information, see on setting up OAuth consent screen. To set up app token and authentication, see using OAuth 2.0 for Web Server applications. |
In order to start using the Google Cloud Speech module, it is necessary to enable the Cloud Speech-to-Text service.
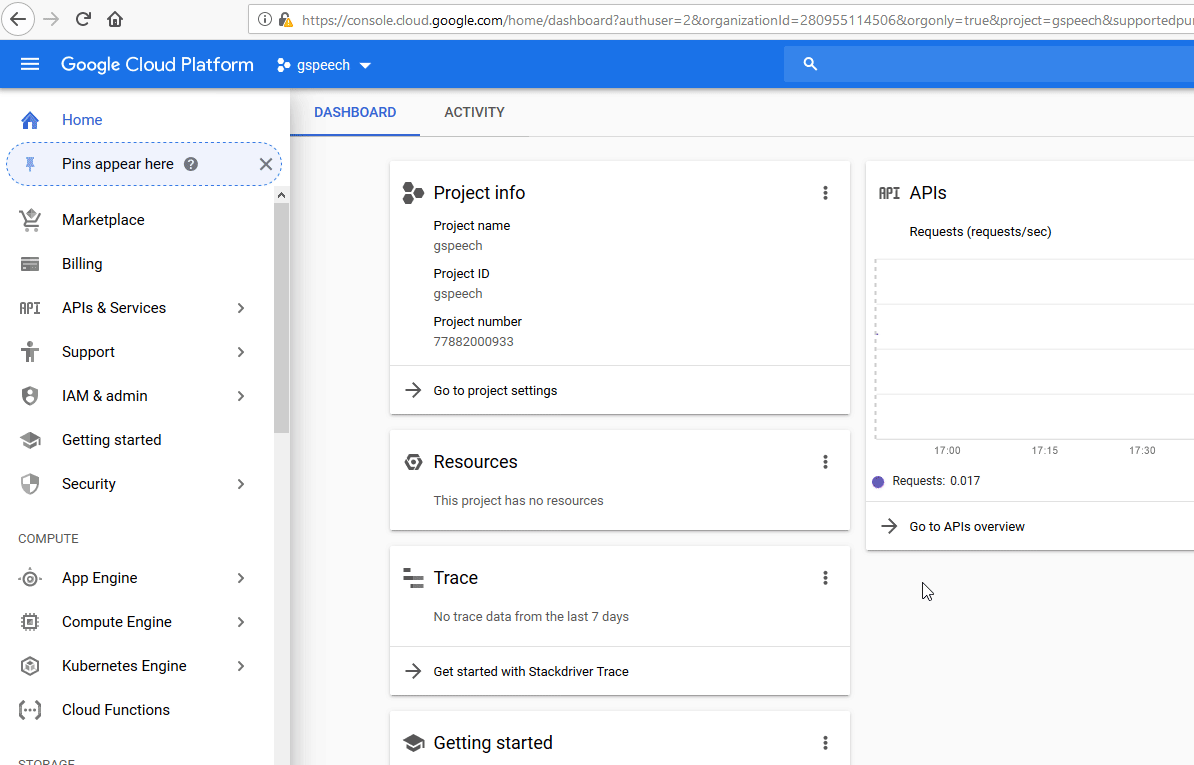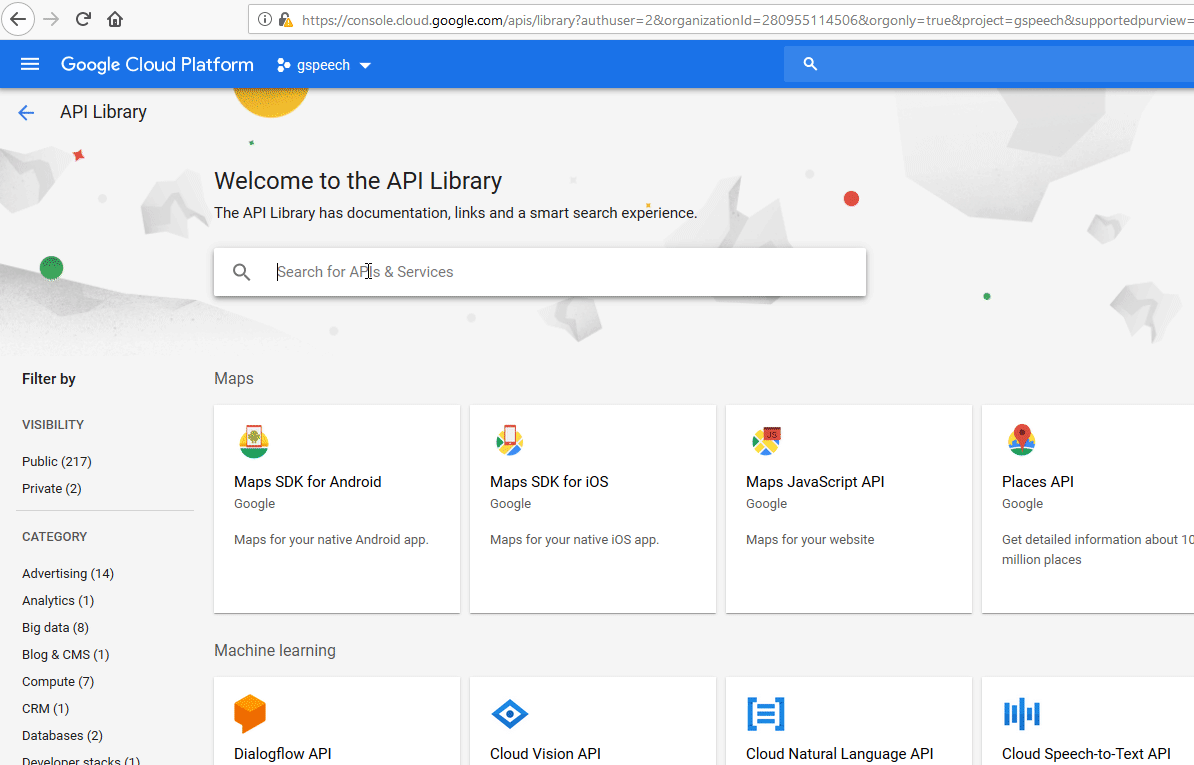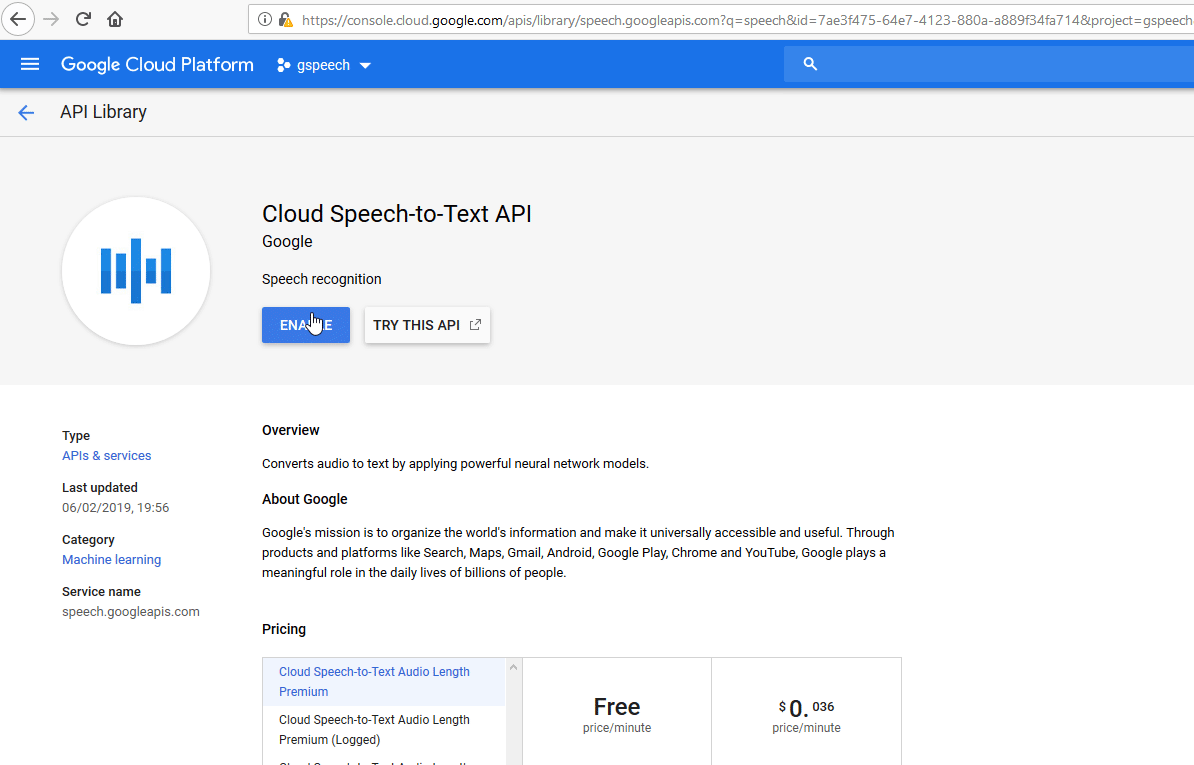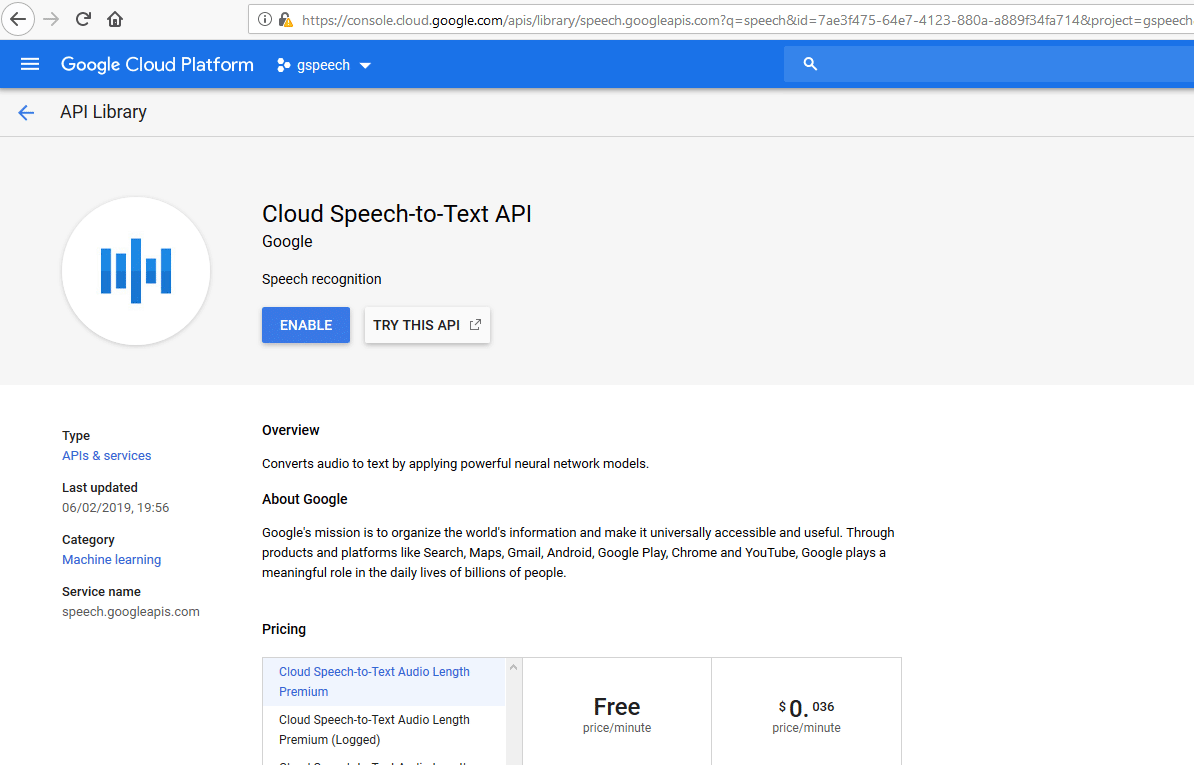
Transcribes long audio files (longer than 1 minute) to text using asynchronous speech recognition. The name of the recognized file is provided. The module Google Cloud Speech > Operation: Get is then needed to retrieve the recognized text.
|
Note |
|---|---|
|
The maximum file size for recognition is 10 485 760 bytes. |
|
Connection |
Establish a connection to your Google Cloud account. |
||||||||||||||||||
|
Source file |
Map the audio file you want to convert to text. If left empty the File URI must be provided. This field is mandatory. |
||||||||||||||||||
|
File URI |
URI that points to the file that contains audio data. The file must not be compressed (for example, gzip). Currently, only Google Cloud Storage URIs are supported, which must be specified in the following format: |
||||||||||||||||||
|
Audio Channels Count |
Enter the number of the audio file channels. ONLY set this for MULTI-CHANNEL recognition. Valid values for LINEAR16 and FLAC are
|
||||||||||||||||||
|
Enable separate recognition per channel |
Enable this option and set the Audio Channels Count to more than 1 to get each channel recognized separately. The recognition result will contain a channelTagfield to state which channel that result belongs to. If this option is disabled, the module will only recognize the first channel.
|
||||||||||||||||||
|
Language Code (BCP-47) |
Enter the language code. The language of the supplied audio as a BCP-47 language tag. Example: “en-US”. See Language Support for a list of the currently supported language codes. You can use BCP-47 validator. This field is mandatory. |
||||||||||||||||||
|
Additional language tags |
Add more language codes if needed. See Language Support for a list of the currently supported language codes. If alternative languages are listed, recognition result will contain recognition in the most likely language detected including the main Language Code. The recognition result will include the language tag of the language detected in the audio.
|
||||||||||||||||||
|
Audio Encoding |
Select the encoding of the audio file/data. For best results, the audio source should be captured and transmitted using a lossless encoding (
|
||||||||||||||||||
|
Sample rate in Hertz |
Enter the sample rate in Hertz of the audio data. Valid values are 8000-48000. 16000 is optimal. For best results, set the sampling rate of the audio source to 16000 Hz. If that’s not possible, use the native sample rate of the audio source (instead of re-sampling). This field is optional for |
||||||||||||||||||
|
Number of alternatives |
The maximum number of recognition hypotheses to be returned. Valid values are |
||||||||||||||||||
|
Profanity filter |
If this option is enabled, the server will attempt to filter out profanities, replacing all but the initial character in each filtered word with asterisks, e.g. “f***”. If this option is disabled, profanities won’t be filtered out. This field is optional. |
||||||||||||||||||
|
ArrayWithin a bundle, data items of the same type are sometimes in an array. You can find an array by looking at the details of a bundle. Depending on the details of your scenario, you can map other modules to a specific item in an array or use iterators and aggregators to manipulate your data into other formats. When mapping,... More of SpeechContexts |
Enter “hints” to speech recognizer to favor specific words and phrases in the results. A list of strings containing word and phrase “hints” allows the speech recognition to more likely recognize them. This can be used to improve the accuracy for specific words and phrases, for example, if specific commands are typically spoken by the user. This can also be used to add additional words to the vocabulary of the recognizer. See usage limits. |
||||||||||||||||||
|
Enable word time offsets |
If this option is enabled, the top result includes a list of words and the start and end time offsets (timestamps) for those words. If this option is disabled, no word-level time offset information is returned. The option is disabled by default. This field is optional. |
||||||||||||||||||
|
Enable word confidence |
If this option is enabled, the top result includes a list of words and the confidence for those words. If this option is disabled, no word-level confidence information is returned. The option is disabled by default. This field is optional. |
||||||||||||||||||
|
Enable automatic punctuation |
If this option is enabled, it adds punctuation to recognition result hypotheses. This feature is only available in selected languages. Setting this for requests in other languages has no effect at all. The option is disabled by default. This field is optional.
|
||||||||||||||||||
|
Enable speaker diarization |
This option enables speaker detection for each recognized word in the top alternative of the recognition result using a speakerTag provided in the WordInfo. |
||||||||||||||||||
|
Diarization speaker count |
Enter the estimated number of speakers in the conversation. If not set, defaults to ‘2’. Ignored unless Enable speaker diarization is enabled. |
||||||||||||||||||
|
Metadata |
Description of audio data to be recognized.
|
||||||||||||||||||
|
Model |
Select the model best suited to your domain to get the best results.
|
||||||||||||||||||
|
Enhanced |
Enable this option to use an enhanced model for speech recognition. You must also set the You must opt-in to the audio logging using the instructions in the data logging documentation. |
![[Warning]](https://docs.boost.space/wp-content/themes/bsdocs/docs-parser/HTML/css/image/warning.png)
Retrieves the latest state or the result of a long-running operationlong-running operationAn operation is a task performed by module. More. You can then use the result (text) in the following modules of your choice.
|
Connection |
|
|
Name |
Enter the name of the operation. The name can be retrieved using the Speech: Long Running Recognize module. 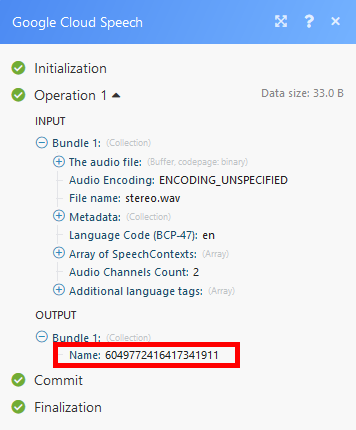 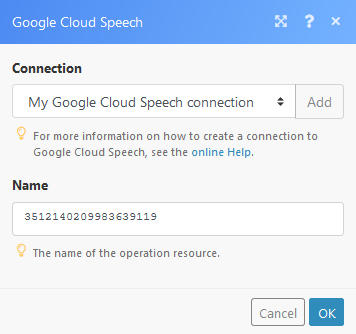 |
This module returns the recognized text for short audio (less than ~1 minute). To process a speech recognition request for long audio, use the Speech: Long Running Recognize module.
The module Speech: Recognize contains the same options as the use the Speech: Long Running Recognize module.
The only difference is, that the recognition is done immediately. You do not need to use the OperationsAn operation is a task performed by module. More: Get module.
