| Active with remarks |
|---|
| This application needs additional settings. Please follow the documentation below to create your own connectionUnique, active service acces point to a network. There are different types of connections (API key, Oauth…). More. |
Klippa modulesThe module is an application or tool within the Boost.space system. The entire system is built on this concept of modularity. (module - Contacts) More allow you to automate document management, classification, and data extraction from your Klippa account.
Getting Started with Klippa
Prerequisites
-
A Klippa account – create an account at klippa.com
Connect Klippa to Boost.spaceCentralization and synchronization platform, where you can organize and manage your data. More IntegratorPart of the Boost.space system, where you can create your connections and automate your processes. More
To connect your Klippa to Boost.space Integrator you need to obtain an API key by contacting the Klippa team at Klippa Support team and inserting it in the Create a connection dialog in the Boost.space Integrator moduleThe module is an application or tool within the Boost.space system. The entire system is built on this concept of modularity. (module - Contacts) More.
1. Log in to your Boost.space Integrator account and add a module from the AX Semantics app into an Boost.space Integrator scenarioA specific connection between applications in which data can be transferred. Two types of scenarios: active/inactive. More.
2. Click Add next to the Connection field.
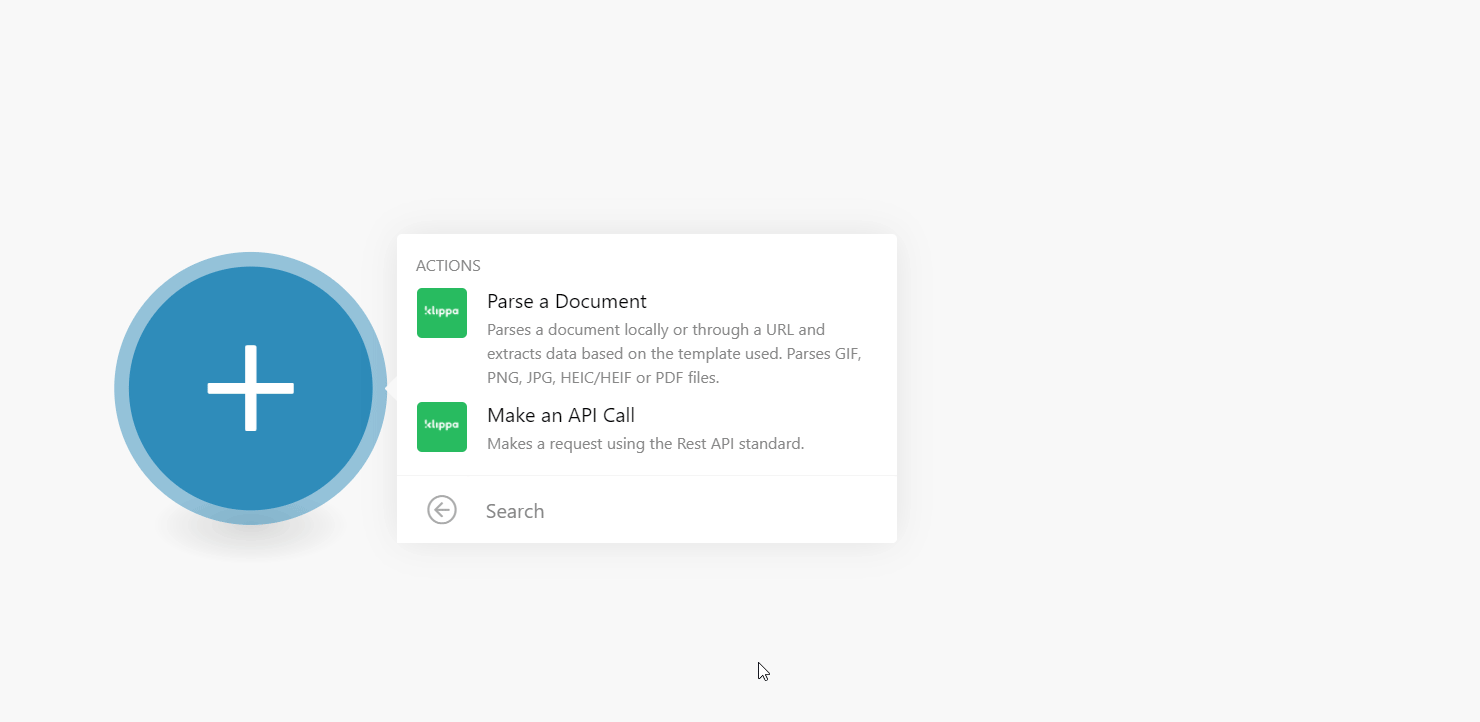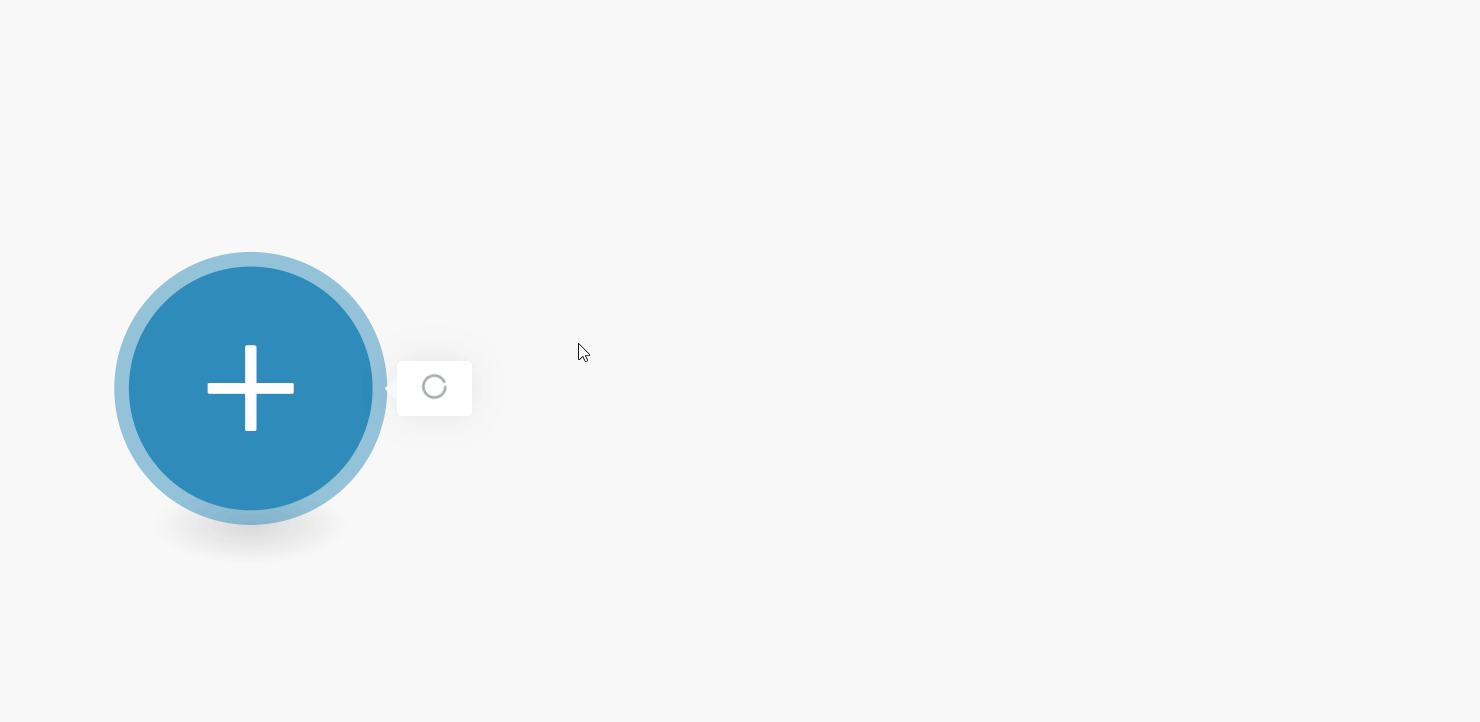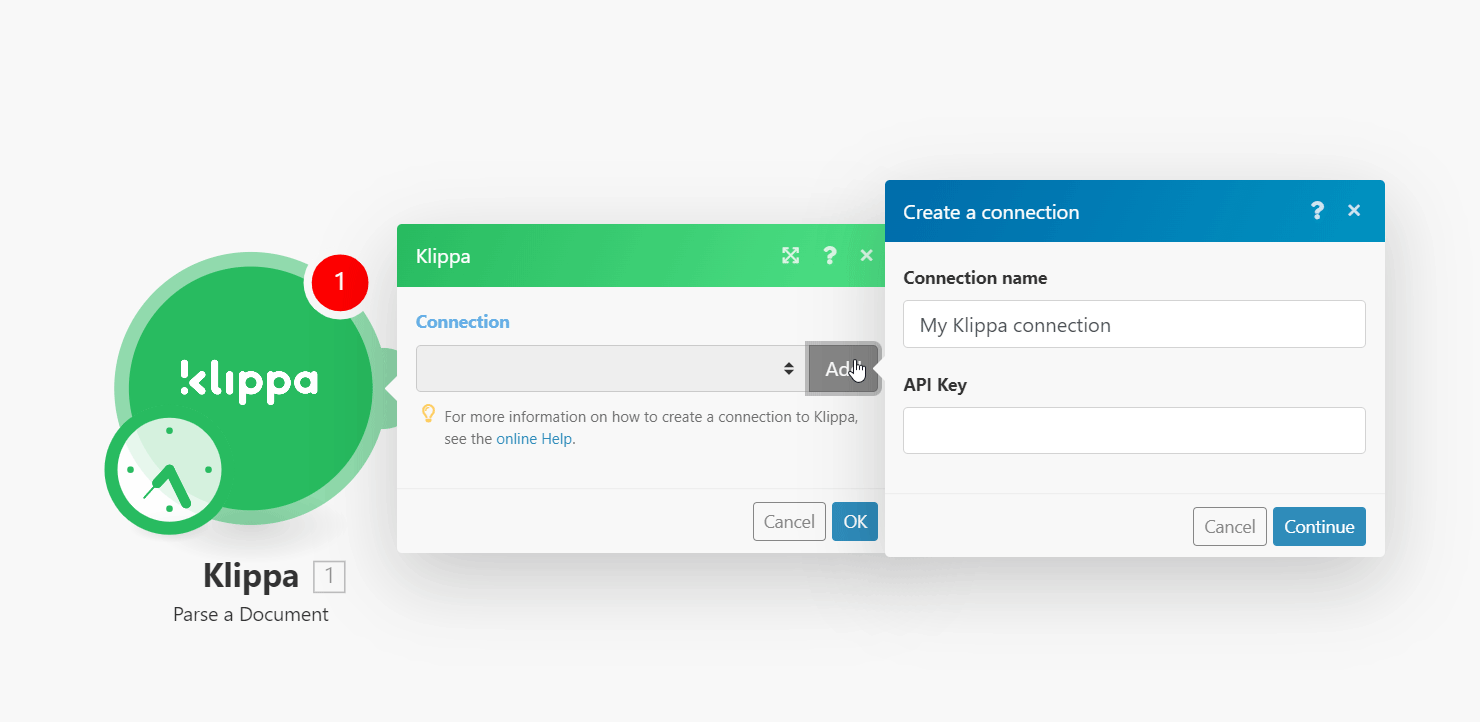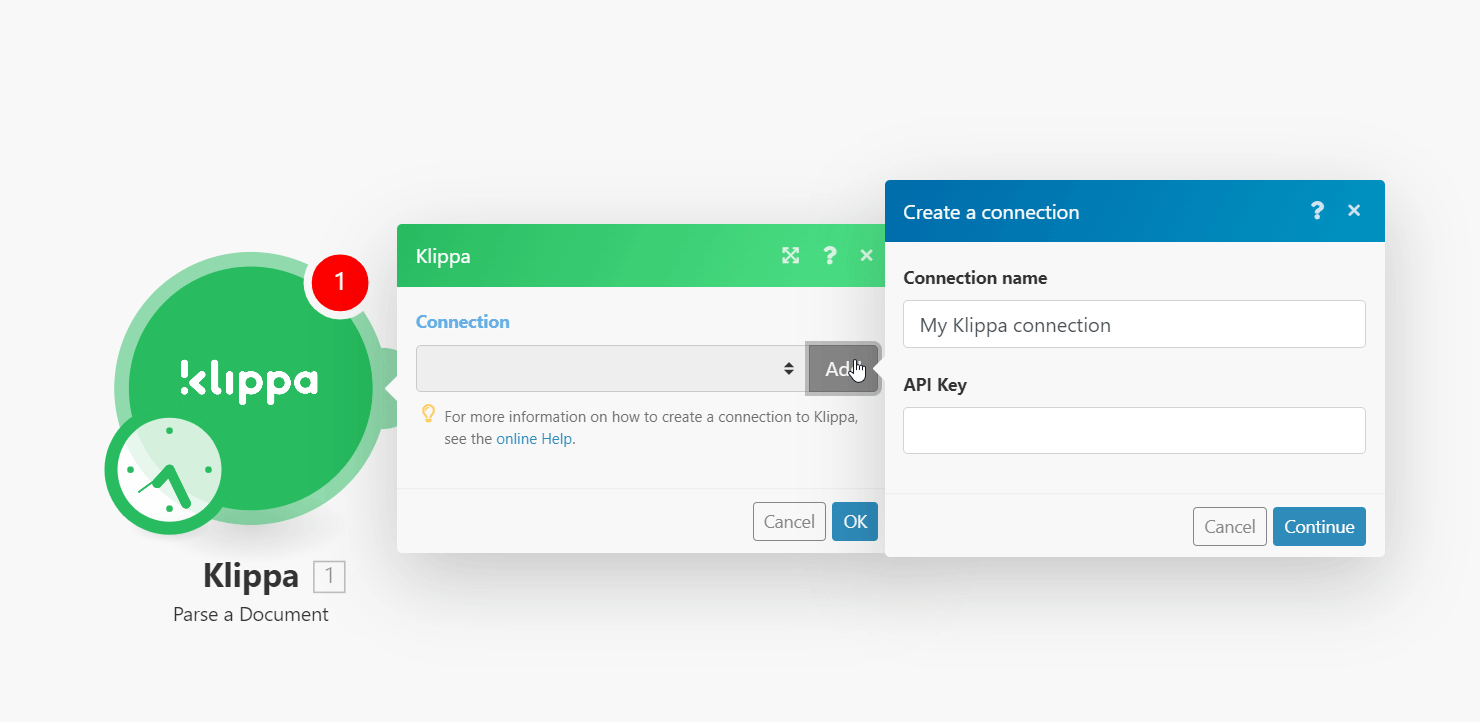
3. In the Connection name, enter a name for the connection.
4. In the API Key field, enter the API key received from the Klippa support team and click Continue.
The connection has been established.
Parse a document in the Klippa system and return all information in JSON.
|
Connection |
|
|
Document Source |
Select the source of the document:
|
|
Document URL |
Enter (map) the document URL address which you want to parse. |
|
Source File |
Add the file details:
|
|
TemplateTemplates are predefined scenarios that you can expand and customize to create new scenarios. You can then share these with friends and colleagues. More |
Select or map the template to use for parsing the document. |
|
PDF Text Extraction |
Select or map the option to extract the PDF text. For example, full, fast. |
|
UserCan use the system on a limited basis based on the rights assigned by the admin. More Data |
Enter (map) the user metadata in JSON format to give to the parser. This field only works with templatesTemplates are predefined scenarios that you can expand and customize to create new scenarios. You can then share these with friends and colleagues. More that are configured to accept user data. |
|
User Data Set External ID |
Enter (map) the User Data Set External ID. |
|
Hash Duplicate Group ID |
Enter (map) an identifier to use when saving or detecting hash duplicates. It helps you to allow to have the same document scanned more than once for multiple groups. When doing a scan, the combination of the Hash Group ID and the document hash are used to detect the duplicates. This value is saved hashed on Klippa’s side. The common use cases are Company ID, Campaign ID, and User ID. |
Performs an arbitrary authorized API call.
|
Connection |
|
|
URL |
Enter a path relative to For the list of available endpoints, refer to the Klippa API Documentation. |
|
Method |
Select the HTTP method you want to use: GET to retrieve information for an entry. POST to create a new entry. PUT to update/replace an existing entry. PATCH to make a partial entry update. DELETE to delete an entry. |
|
Headers |
Enter the desired request headers. You don’t have to add authorization headers; we already did that for you. |
|
Query String |
Enter the request query string. |
|
Body |
Enter the body content for your API call. |
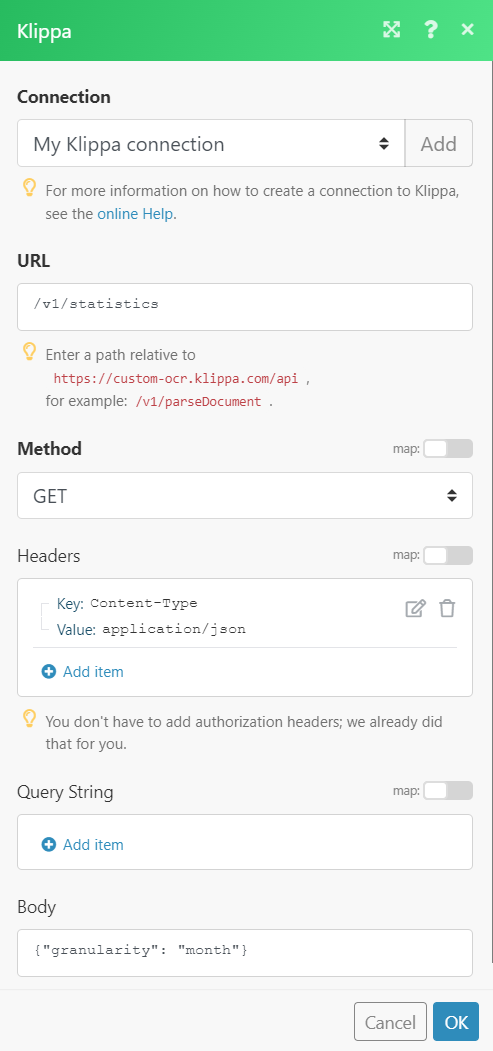
The following API call returns API usage statistics from your Klippa account:
URL: /v1/statistics
Method: GET
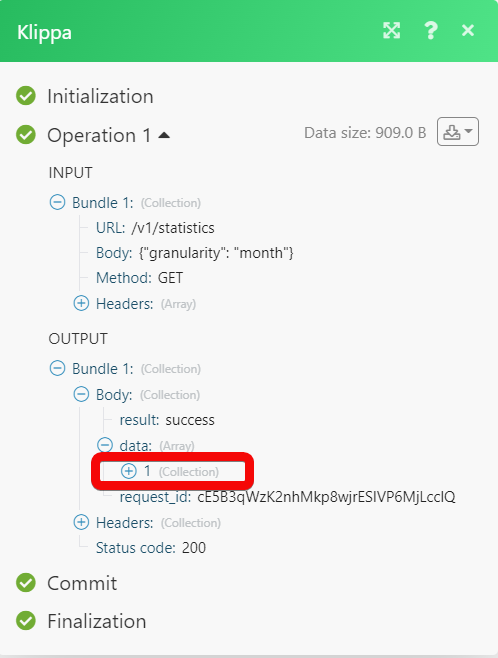
Matches of the search can be found in the module’s Output under BundleA bundle is a chunk of data and the basic unit for use with modules. A bundle consists of items, similar to how a bag may contain separate, individual items. More > Body > data.In our example, 1 recordOne row in the Boost.space database. These are individual rows under spaces in each module. For example single products, but not their variants. More is returned:
These settings can be used if you want to modify the parser more.
Select a template for the parser to identify what kind of document it would be. It can be that when changing the template settings, the output data is different.
Use full when you want the best quality scan, use fast when you want fast scan results. Fast will try to extract the text from the PDF. Full actually scans the full PDF which is slower.
The User Data allows for sending additional data into the parser and can be used to enable extra features, improve the recognition of certain fields and improve the processing speed. All fields are optional, documents may be submitted without this field. For more information, refer to the Klippa API documentation.
This option is only available when you have custom Datasets and the API has access to these datasets, For more information, contact the Klippa support team.
The ID of the dataset in your own system, The system returns this id in the merchant_id field if there is a match.
An identifier to use when saving or detecting hash duplicates. This way you can allow to have the same document scanned more than once for multiple groups. When doing a scan, the combination of the Hash Group ID and the document Hash will be used to detect duplicates. This value is saved hashed on the side of Klippa. The common use cases are Company ID, Campaign ID, and User ID.